








Data anomalies in Machine Learning (ML) can pose significant challenges to the accuracy and reliability of models. Detecting and mitigating these anomalies are crucial processes for managing ML models and their applications. Data anomalies can arise from a variety of factors that are essential for data scientists and knowledge workers to handle:
- Human errors
- Feature inaccuracy
- Dataset inadequacies
- ML model malfunctions
In this article, we will dive deeper into the complexities and types of data anomalies, explore their impact on ML outcomes, and provide insights into various methods for detecting and mitigating them.
The best practices and future trends in data anomaly detection can help shed some light on the evolving nature of this critical aspect of machine learning.
Understanding Data Anomalies in ML

Data anomalies typically refer to irregularities or deviations from expected patterns within a dataset. In the context of machine learning, these anomalies can negatively affect model performance and compromise prediction accuracy.
Understanding and identifying these anomalies is essential for developing robust ML systems. By recognizing patterns that deviate from the norm, ML models can be trained to make more accurate predictions and avoid being negatively influenced by misleading data.
Let’s look at some aspects that are positively affected by the presence of data anomalies:
1. Developing Robust ML Systems
Recognizing and understanding data anomalies are fundamental for developing robust ML systems. This process involves evaluating the complexities of the dataset and detecting unexpected patterns or irregularities that could potentially misdirect the model learning process.
2. Enhancing Model Predictions
By developing awareness of anomalies, machine learning models can be trained to navigate through data problems and make more informed and accurate predictions. Learning algorithms that are equipped with the ability to distinguish between normal patterns and anomalies can optimize their predictive capabilities.
The Impact of Data Anomalies in Machine Learning
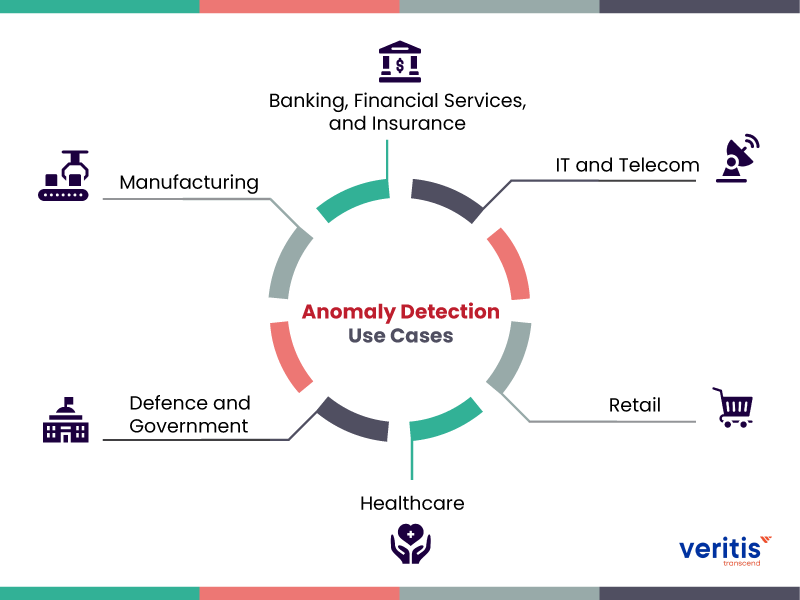
The impacts of data anomalies in ML are layered, as they can affect the reliability, interpretability, and deployment capabilities of models. Incorrect data or unexpected patterns can hinder the development of reliable models and lead to inaccurate predictions.
Let’s take a look at the issues that data anomalies can bring about:
1. Biased Models
Incorrectly gathered datasets can significantly contribute to biased models. These biases can occur as the learning algorithms are misled by anomalous data points, changing their understanding of the hidden patterns and trends in the dataset.
2. Inaccurate Predictions
Data anomalies undermine the accuracy of predictions. When ML models are trained on datasets containing anomalies, they may produce predictions that deviate from the unadulterated data, affecting the reliability of the prediction results.
3. Real-world Consequences
Beyond the controlled modeling environment, the influence of data anomalies can affect decision-making processes based on models adversely affected. This can have consequences in strictly regulated areas such as finance and healthcare, where accurate results are critical.
4. Ethical Challenges
Addressing data anomaly issues is imperative for ensuring the ethical use of ML models. Biased models and inaccurate predictions can create unfair outcomes and bolster existing disparities. Anomaly detection and mitigation are necessary for promoting ethical ML model practices.
5. Trust in ML Models
Data anomalies reduce trust in ML models by introducing inaccuracies that create unreliable prediction systems. By effectively addressing the impact of anomalies, data scientists and knowledge workers can develop confidence in the reliability of their automated systems.
Types of Data Anomalies
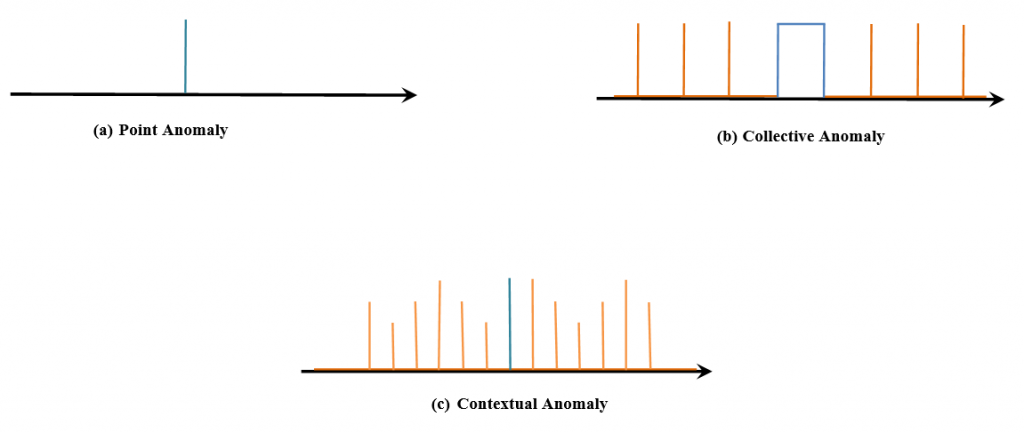
1. Point Anomalies
Point anomalies refer to individual data points that deviate from expected patterns in the dataset. Identifying and addressing these anomalies is imperative for maintaining the integrity of the ML model training process and preventing biased outcomes.
Acknowledging and handling point anomalies mitigates the risk of inaccurate model outcomes due to the negative influence of individually mishandled data points.
2. Contextual Anomalies
Contextual anomalies occur when the occurrence of a particular data point is considered anomalous within a specific context. Understanding the contextual relevance of the data is important for accurately detecting and handling such anomalies.
Contextual anomalies require a nuanced outlook, as a value that might be considered normal in one context could potentially be anomalous in another.
3. Collective Anomalies
Collective anomalies typically involve a group of data points that exhibit anomalous behavior when evaluated together. Detecting these anomalies requires the analysis of relationships and interactions among data points, which presents a unique set of challenges in anomaly detection.
The identification of collective anomalies involves an understanding of the collective behavior of data points rather than focusing on individual data features.
Causes of Data Anomalies in ML
1. Errors in Data Collection
Data anomalies can be caused by errors during the data collection process. Inaccuracies, mislabeling of data values, or inconsistencies in data entry contribute to the presence of anomalies within the dataset.
Cutting-edge platforms such as MarkovML use machine learning algorithms to proactively anticipate and address issues with data quality metrics. Knowledge workers gain the ability to adapt to changing data patterns, making them especially proficient in extensive and intricate datasets.
2. Sensor Malfunctions
Malfunctions or inaccuracies in sensor readings can introduce data anomalies. Identifying and mitigating these anomalies is essential for maintaining the reliability of sensor-based ML models.
3. Fraudulent Activities
For applications such as fraud detection, anomalies can be introduced from fraudulent activities that are different from typical user behavior. Detecting and mitigating these anomalies is essential for preserving the integrity of the ML model.
4. Rare Events
Uncommon scenarios not properly represented in the training data can lead to anomalies. Strategies that help address rare events ensure that the ML model is robust at handling unforeseen circumstances.
Detecting Data Anomalies in Machine Learning
Detecting data anomalies is a critical step in building resilient machine-learning models. Various methods can be used, ranging from statistical approaches to sophisticated ML-based techniques.
1. Statistical Methods
- Z-Score
The Z-Score is a statistical measure that quantifies how far a data point is from the mean value of a dataset. Data points with higher Z-scores are considered potential anomalies, which makes this method effective for detecting point anomalies.
- Modified Z-Score
The Modified Z-Score considers the median and median absolute deviation instead of the mean and standard deviation. This makes it less sensitive to outliers, providing a more accurate representation of anomalous data points.
- Tukey’s Method
Tukey’s Method utilizes the interquartile range to identify outliers in a dataset. By defining a threshold based on the spread of the middle 50
2. Machine Learning-Based Approaches
- Isolation Forests
Isolation Forests are tree-based models designed to isolate anomalies by creating partitions in the data. Anomalies are then identified based on their shorter average path length within the constructed trees.
- One-Class SVM
One-Class Support Vector Machines (SVM) classify data points as either normal or anomalous. These models learn the characteristics of normal data during training and detect deviations during testing.
- Autoencoders for Anomaly Detection
Autoencoders, a type of neural network, can be trained to reconstruct input data and identify anomalies by measuring the difference between the input and the reconstructed output.
3. Ensemble Methods
- Combining Multiple Models for Robust Anomaly Detection
Ensemble methods combine the outputs of multiple anomaly detection models. This approach enhances the overall robustness and reliability of anomaly detection, as it makes use of the unique strengths of individual models and mitigates their weaknesses.
Mitigating Data Anomalies
Detecting anomalies is only the first step, as mitigating their impact is equally necessary for the iterative development and refinement of ML models. Several strategies can be deployed to address data anomalies effectively.
1. Data Cleaning and Pre-Processing Techniques
- Outlier Removal
Removing identified outliers from the dataset helps reduce the influence of anomalous data points on the training process. This creates a cleaner dataset and improves the overall performance of ML models.
- Imputation Strategies
Imputation involves replacing anomalous values with estimated or imputed values. Careful selection of imputation strategies ensures that the imputed values are congruent with the overall characteristics of the dataset.
- Feature Engineering for Anomaly Reduction
Engineered features can improve the model’s ability to recognize and adapt to data patterns, reducing the impact of anomalies. Thoughtful feature engineering improves the model’s capacity to generalize and make accurate predictions.
2. Handling Imbalanced Datasets
- Resampling Techniques
Resampling techniques address imbalances in the dataset by adjusting the proportion of normal and anomalous instances. Oversampling the minority class or undersampling the majority class helps create a more balanced training dataset.
- Synthetic Data Generation
Generating synthetic data can supplement the training dataset in cases where the occurrence of anomalies is limited. This approach creates a more representative dataset for training anomaly detection ML models.
3. Continuous Monitoring and Updating
- Establishing Monitoring Systems
Continuous monitoring systems allow real-time detection and responses to potential emerging anomalies. Regularly monitoring data streams and model outputs ensures timely detection and mitigation of data issues.
- Adapting to Evolving Data Patterns
As data patterns evolve over time, models need to develop and adapt. Regularly updating models with new data and retraining them ensures that the model remains effective in detecting and mitigating anomalies.
Best Practices for Anomaly Detection in ML
To achieve effective anomaly detection for ML models, it is essential to follow practices that enhance their overall reliability and performance.
1. Define Data Anomalies Clearly
Establish clear definitions of what constitutes data anomalies in the context of your specific ML model and application.
2. Regularly Update Models
Regularly updating models with fresh data can help account for evolving patterns and trends in the dataset.
3. Utilize a Variety of Approaches
Combine statistical methods, ML-based approaches, and ensemble methods for a comprehensive and robust anomaly detection framework.
4. Invest in Quality Data
Ensure the quality and accuracy of the training data, as the effectiveness of anomaly detection is reliant on the quality of the input data.
5. Implement Continuous Monitoring
Set up monitoring systems to detect anomalies in real-time and enable prompt responses to any emerging issues.
6. Document and Analyze Anomalies
Keep detailed records of detected anomalies, analyze their causes, and use this information to continuously improve anomaly detection strategies.
Future Trends
The landscape of anomaly detection in machine learning is dynamic, with ongoing advancements and emerging trends shaping its future. The development of more sophisticated algorithms and the incorporation of explainable AI is likely to address challenges associated with model interpretability, fostering greater trust in anomaly detection systems.
1. Sophisticated Algorithm Development
Future trends indicate a continuous focus on the development of more sophisticated algorithms for anomaly detection. These advanced algorithms will be designed to recognize and understand complex patterns within datasets, improving the accuracy and efficiency of anomaly detection processes.
The evolving algorithms will enable machine learning models to adapt dynamically to changing data patterns, ensuring robust anomaly detection across diverse scenarios.
2. Incorporation of Explainable AI
Addressing challenges related to the interpretability of ML models is crucial for anomaly detection. The incorporation of explainable AI techniques aims to provide transparency in the decision-making process, making it easier for users to trust anomaly detection systems.
3. Automation and Real-time Processing
Future trends in anomaly detection point towards an increased emphasis on automation, reducing the manual efforts required for model maintenance and monitoring. Future systems are likely to focus on enhancing the speed and efficiency of anomaly detection for quicker responses to emerging issues.
4. Integration with Edge Computing
The integration of anomaly detection with edge computing allows for decentralized processing of data closer to its source. This aims to reduce latency in anomaly detection by processing data locally.
Conclusion
Detecting and mitigating data anomalies in machine learning is essential for building reliable and trustworthy models. By understanding the types and causes of anomalies, establishing effective detection methods, and adopting robust mitigation strategies, data scientists and knowledge makers alike can enhance the overall performance and resilience of ML applications.
When selecting the right platform for ensuring data quality and reducing the possibility of anomalies, factors like the specific challenges and the complexity of the data should be considered.
For instance, MarkovML’s comprehensive No-Code Auto-EDA allows knowledge makers to identify data gaps, outliers, and patterns to make informed modeling decisions. MarkovML’s Intelligent Data Catalog organizes AI data, metrics, and insights from ML workflows to facilitate easier transparency and documentation of data anomalies and their mitigation.



