There’s been a lot of hype recently surrounding quantum computers. From IBM releasing their new 127-qubit Eagle Chip, to Xanadu unveiling their Quantum Codebook, there’s been a lot going on in the industry!
However, this news might lead one to wonder: Sure, the tech’s cool and all, but what can I actually use a quantum computer for?
IBM’s new Eagle Chip, the first of its kind with over 100 qubits. New Atlas
Before we get started, a few important notes:
This is meant to be a beginner-friendly walkthrough of Grover’s algorithm, but you should have some knowledge of quantum mechanics.
I was as new to this as you are a week ago. With enough time, the idea will ‘click’. Trust me.
Remember Dictionaries?
When was the last time you used a dictionary? Not an online one (I’m looking at you Google Translate), but a printed, physical dictionary. It’s been a while, hasn’t it?
There’s a good reason why we moved on from them too: they’re too time consuming. I could spend an entire French class desperately flipping through the pages just to find one word.
And this is the time it takes to search through structured data — sorted according to a meaningful metric, in this case alphabetically.
This dictionary is an example of a structured database. iStock
What if I came up to you in class, ripped all of your dictionary pages out, jumbled them up, and handed them back to you. How long would it take you to find the definition of sortir now?
This is what computer nerds like to call unstructured data, where we just have a bunch of random data flowing in. No more classement here.
Sorting Through a Database, Classical Style
Your teacher asks you to find the definition of travailler in the stack of (virtual) papers. Being practically illiterate in French, you have no clue what the word means. Luckily, you’re very literate in Python, so you design and algorithm to find the definition.
Let’s say that we define this stack as a list of length N. This list is an unstructured database, and I want to find a specific value called w (for winner). Assuming that this winning quality is unique to w (i.e. w is our only solution), we must sort through the list N/2 times on average, since the average placement of w is in the middle of the list. At worst, we need to sort through the list N times, where w is placed at the very end of that list.
The code sorts through the streaming list, and returns the index of the streaming service. App Dividend
As you might have guessed, running this algorithm on longer and longer lists will increase the time it takes to find w. We call this O(N) time. The time it takes to carry out this operation is directly based on the length, N, of the list.
As a visual learner, charts always help. Here’s one to visualize the average runtime of an O(N) algorithm.
Average runtime of O(N) algorithm. Length of list N on x-axis, runtime in seconds on y-axis.
Let’s add some context.
In our example, each data point that I process adds 1 second to the total runtime. In a list of 10,000 items, it takes me almost an hour and a half on average to find w in the list.
Expand that to 80,000 items, and the time has increased to 11 hours.
The world’s largest dictionary has over 145,000 words. Get ready to wait a while…
Lov Grover’s Quantum Approach
Sometime in 1996, an Indian-American computer scientist publishes a paper that will put down his name in the Quantum Computing Hall of Fame. Lov Grover is his name, optimizing unstructured search problems is his game.
He suggests implementing a little trick in quantum known as Amplitude Amplification to significantly decrease the amount of time it would take to find our winner w.
What is this mystical Amplitude Amplification, and what does it do?
Great question. As you may remember, all quantum states have their own amplitudes. With the Born Rule, this amplitude α² is the probability that the qubit collapses into state |0〉 or state |1〉. So why not amplify the amplitude (insert laugh here) of the winner w, and shrink the other states’ amplitudes? This would lead us to state w with near-certainty.
Amplifying the amplitude of state w would look something like this. Qiskit
At it’s core, the algorithm consists of 3 main steps:
Initializing the circuit
Inverting the phase of state w
Un-inverting the phase of state w, where w now has a larger amplitude and consequently, larger probability of being measured
But what does this all mean?
This part gets a little tricky, but stay with me. An example will make everything super clear. I’ll include some Qiskit code along the way to see how we can program this example, as well as some geometrical representations.
Grover’s Algorithm Step by Step, 2 Qubits
2 qubits can represent a total of 4 states (|00〉, |01〉, |10〉, |11〉), so the length of list N is 4. Out of these states, we will search for |11〉, so our winning state w is |11〉.
At this point, if we were to guess what the state of w was, it would take us on average N/2 tries to guess right. Any guess at the position of w has an equal chance of being correct, which can be modeled as a equal superposition. We can achieve this state by applying a Hadamard, which puts a qubit into superposition, to each of our qubits.
The uniform superposition state |s〉 is coded:
Created a function to initialize qubits, called it, and drew the resulting circuit.
Good start.
How do we specify the exact state that we are searching for?
We need to somehow ‘mark’ the state we are searching for. An intuitive way to do this would be to apply a negative phase to w. The gates that we use to apply this negative phase are called an oracle.
To mark |11〉, we use the Controlled-Z gate. The special thing about this gate is that it only applies a negative phase when both qubits are in state |11〉. This means that it leaves all other states untouched.
Here’s how it’s coded:
We apply the cz-gate after initialization.
Diversion: Clearly with Geometry
We can imagine the states |w〉 and |s〉 span a 2-dimensional vector space. That’s just fancy lingo for saying that any scalar multiplication and addition of the two vectors will cover an entire 2-D plane.
The two states aren’t completely perpendicular, since the state |w〉 does appear in the uniform superposition |s〉. What we want to do is draw a state where there is no contribution of |w〉, which we will call |s〉. This will help with visualization, but isn’t actually present on the quantum computer when performing the algorithm.
We can then use the oracle we have created to apply a negative phase to |s〉. Right now, the s state is ½(|00〉 + |01〉 + |10〉 + |11〉). Again, the oracle will only act on the contribution of |w〉 in the uniform superposition |s〉, so we will end up in state ½(|00〉 + |01〉 + |10〉 -|11〉). Notice that the minus sign only appears in front of state |11〉.
This will also look like a reflection of |s〉 about |s〉 by θ.
Uω is our oracle, which acts on the state |s〉. The end result is a negative phase on the contribution of |w〉 in |s〉. Qiskit
Since the oracle is usually designated by Uω, we can designate the new state as Uω|ψt〉. We can say that this state is the original superposition, acted on by Uω. We’ve defined the state as Uω|ψt〉 instead of Uω|s〉 to improve clarity.
This negative phase can’t be measured, since the amplitude squared will always yield a positive number.
As you have probably guessed, the negative phase of |w〉 also has an effect on the average amplitude of state |s〉, lowering it by a little bit:
Before and after the oracle. The dashed line in the right visual indicates the new average amplitude. Qiskit
The last step is to increase the amplitude of |w〉. We can do this by applying another reflection. This second reflection is called the diffuser operator, and performs the reflection 2|s〉〈s|- 1.
This expression can be visualized, making it much easier to understand its function. Below, the diffuser is Us.
The Us gate acts upon the Uω|ψ〉 state, corresponding to a rotation of 2θ about the |s〉 state. Qiskit
Here’s what the amplitude implications of the reflection are.
The amplitude of state |w〉 is amplified, while the other amplitudes are diminished. Qiskit
Awesome. We now have a state where |w〉 is amplified. But how do we make sure that we measure |w〉 most of the time, so that the amount of times |w〉 is measured is significantly larger than the other processes?
Simple. Repeat steps 2 and 3. Each time they’re repeated, they push the new state closer and closer to the winning state |w〉 on the vertical axis.
We need to repeat this process around √N times to get an accurate result.
Back to the Code
We’ve created the initial superposition state as well as the oracle, but we are yet to create the diffuser.
As a recap, the first Hadamard’s are the initialization and the CZ after the barrier is our oracle. We apply the H’s, Z’s, CZ, and the last pair of H’s as our diffuser, which accomplishes the reflection 2|s〉〈s|- 1 mentioned above.
We implement the diffuser, and measure the resulting states to 2 classical bits.
This is what the completed circuit looks like. Notice we added measurements at the end, which will map the state of the qubits to classical bits.
Interestingly, this paper by Michael Nielsen and Isaac Chuang proved that only one run through is required to produce an accurate result in this experiment, so there’s no need to repeat any of the reflections.
We need to make sure that this code functions correctly.
The quantum simulator returns the state |11〉: our |w〉 state!
We run the code on a quantum simulator in Qiskit called QASM, which accounts for errors in computation on real quantum devices. The code returns the expected value |11〉, running only once. Looks like the algorithm works!
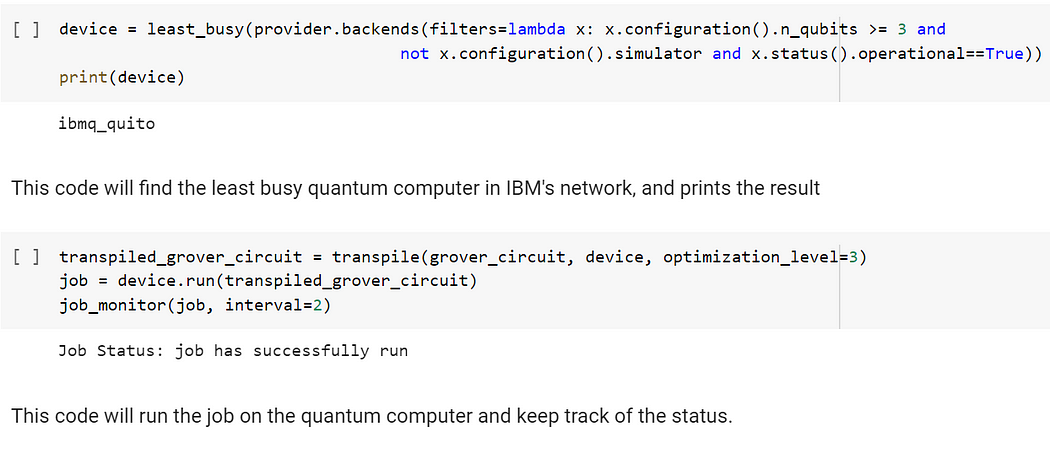
Let’s see it run on a real quantum computer!
Find the least busy quantum computer, and run the job on it. This process took around 10 min.
The other outputs we get are the products of errors in quantum computation.
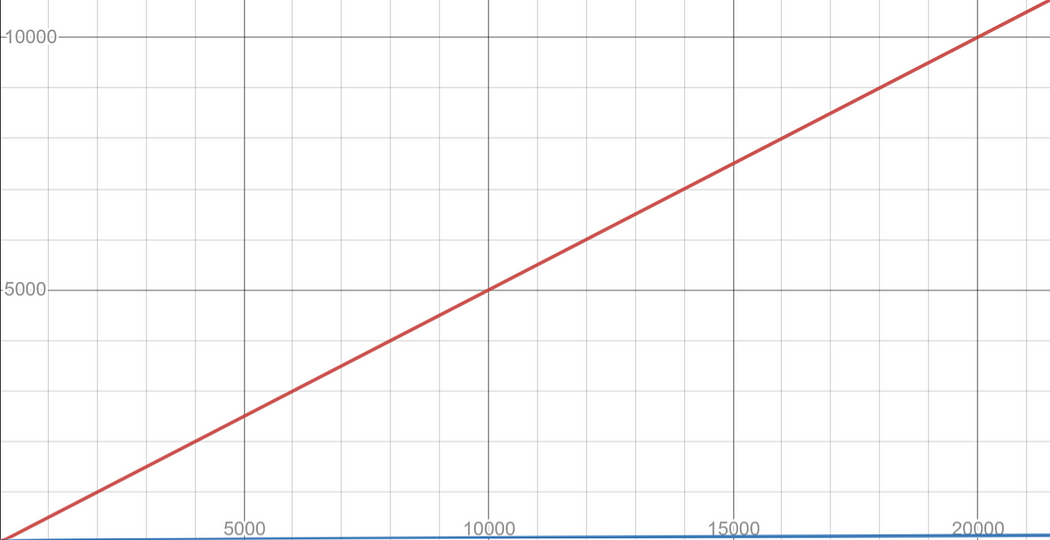
This proves the fact that quantum computation can take as little as O(√N), which is a drastic speed up compared to classical methods, as shown in the graph.
Average Runtime for a Classical Search (red) vs. Grover’s Algorithm Search (blue). Length of N on x-axis, runtime in seconds on y-axis.
3 Qubits For Me
The algorithm is run much the same on 3 qubits.
We’ll look for 2 solutions where length of list N is 8. This is also one of the problems where the paper showed only one run-through of the algorithm was necessary to obtain an accurate measurement.
On the quantum sim, we only get states |101〉 and |110〉, which were the states we were looking for. Let’s test it out on a real quantum computer.
This took about 20 min.
Once again, the other values that appear in our probabilities are errors in the quantum computation.
Key Takeaways:
Grover’s algorithm takes the search of unstructured data from O(N) time to O(√N) time
It uses Amplitude Amplification, which can be visualized as rotations
It is programmable on Qiskit using basic quantum gates
Applications of Grover’s Algorithm:
Data mining: Grover’s algorithm can be used to find patterns in large datasets that would be impossible to find with a classical computer. For example, it could be used to find fraudulent transactions in a financial database or to identify cancer cells in a medical image.
Cryptography: Grover’s algorithm can be used to break cryptographic keys that are currently considered secure. This could have a major impact on the security of online communications and transactions.
Optimization: Grover’s algorithm can be used to solve optimization problems that are difficult or impossible to solve with a classical computer. For example, it could be used to find the shortest route between two points or to find the optimal investment portfolio..
Limitations of Grover’s Algorithm:
Quadratic speedup: Grover’s algorithm gives a quadratic speedup compared to classical algorithms, which means that it can only provide a significant speedup for some problems that have a large search space. For problems with smaller search spaces, the speedup may not be good enough to justify the use of this algorithm.
Limited by hardware: Grover’s algorithm requires the use of a large number of qubits to achieve a significant speedup, which is currently beyond the capabilities of most quantum hardware. This means that the algorithm may not be practical for many real-world applications until more powerful quantum hardware is developed.
Limited to unstructured search: Grover’s algorithm is designed for unstructured search problems, which means that it may not be applicable to other types of problems such as optimization or simulation.
Error-prone: Grover’s algorithm, like all quantum algorithms, is susceptible to errors due to noise and decoherence. These errors can affect the accuracy and reliability of the algorithm, which can limit its practical use in real-world applications.
Limited applicability in cryptography: Although Grover’s algorithm can be used to break certain cryptographic algorithms, it is not applicable to all types of encryption. For example, public-key encryption is not vulnerable to Grover’s algorithm due to its use of mathematical problems that are not efficiently solvable by quantum computers.
Conclusion:
Overall, Grover’s algorithm is a powerful tool that can be used to solve a variety of problems. For example, it can be used to find patterns in data, break cryptographic keys, and solve optimization problems. As quantum computers become more powerful, Grover’s algorithm will become increasingly important.