Deep Learning has revolutionized various industries, leading to the continuous development of new business applications. However, as AI models are growing in complexity, they require significantly more memory and increasingly powerful computing systems to function effectively.
Global AI market is projected to reach USD 1.85 trillion by 2030.
As AI moves towards edge devices — which often have limited power, memory, and computational capacity — the constraints of modern power-hungry neural networks are becoming increasingly apparent. Conversely, deploying such neural networks in cloud environments incurs significant compute costs, restricting their scalability and profitability for companies.
A promising solution to these challenges is Model Quantization. This article will guide you through the concept of model quantization, exploring its types, techniques, advantages, disadvantages, and more.
Let’s begin by understanding model quantization and why it is necessary.
What is Quantization?
Developers must reduce models’ size without sacrificing accuracy to effectively and efficiently deploy neural networks to cloud and edge devices. Model Quantization addresses these challenges.
To comprehend quantization, you must first understand data types in deep learning, how they are converted and represented to achieve reduced-size models, how quantized and non-quantized models differ, etc.
Data Types
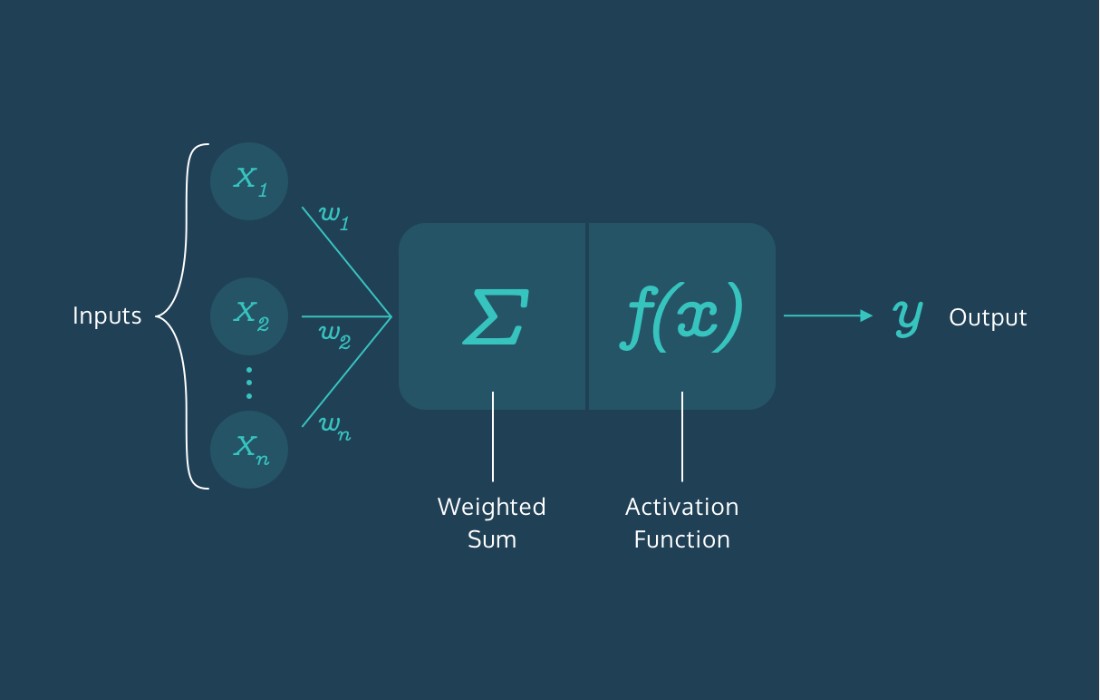
Neural Networks (NN) are floating-point numbers stored in a computer’s memory. As the complexity of NN increases, so does the magnitude of these numbers. In deep learning, 32-bit floats (FP32) and 16-bit floats (FP16) are commonly utilized.

Specific floating-point formats, such as NVIDIA’s TensorFloat (TF32), AMD’s FP24, and Google’s BrainFloat (Bfloat16), are also designed to enhance performance. Moreover, there are various smaller formats known colloquially as minifloats (e.g., FP8,) which find applications in microcontrollers for embedded devices and are supported by new-generation GPUs like NVIDIA’s H100.
All these different formats or representations for storing numbers are crucial as each consumes a specific chunk of memory. Below, we’ve mentioned the bits (b) allocated to different representations (formats)-
Float32 (FP32): 1b for sign, 8b for exponent, 23b for mantissa (fraction)

Float16 (FP16): 1b for sign, 5b for exponent, 10b for mantissa

BF16 (B is Google Brain): 1b for sign, 8b for exponent, and 7b for mantissa

Model Quantization
Model Quantization is a technique that reduces the size of deep neural network (NN) models by converting their weights and other parameters from high-precision floating-point representation to lower precision.
While this approach offers benefits such as increased model performance, better inference speed, reduced memory bandwidth requirements, and improved cache utilization, the primary challenge lies in ensuring that these enhancements do not compromise model accuracy.
Quantization in Deep Networks
Regarding deep learning, you have single or full precision, Float32, and half-precision, which refers to Float16 and BFloat16. By default, full precision is used to train and store deep learning models, and a typical quantization is performed by converting full precision to an INT8 format. Hence, INT8 representation is commonly referred to as “quantized”.
Quantization vs Non-Quantization
Significant differences can exist between quantized and non-quantized models in terms of memory footprint, inference speed, efficiency, and quality of outputs. For instance, while a non-quantized model may occupy approximately 3 GB of memory, its quantized counterpart can reduce this size by 60–70
Similarly, a non-quantized model may require 40 ms per inference and consume 4 joules of power, whereas a quantized model can achieve the same task in 20 ms with 2 joules, marking a 100
However, accuracy can drop. For example, in a computer vision-based NN, a quantized model might produce images with a visual quality of 8 to 10
Challenges of Model Quantization
Quantization is crucial for optimizing machine learning models for deployment in resource-constrained environments like mobile devices and edge computing. By reducing the precision of the model’s parameters and operations, quantization can decrease model size, reduce memory usage, and speed up inference. However, several challenges can arise, including-
1) Requirement of In-depth Knowledge
Different models necessitate distinct approaches to quantization, and you must be well aware of these techniques. Also, successful quantization often requires developers to have prior knowledge of NN architecture and perform extensive fine-tuning.
2) Accuracy vs. Efficiency
Balancing accuracy and model size, especially with low-precision formats like INT8, can be difficult. Their limited dynamic range may compromise accuracy during conversion from higher-precision representations.
For example, while FP16 can replace FP32 with minimal accuracy loss in deep NN inference, smaller dynamic range formats like INT8 present a more significant challenge. A key thing to remember is that during quantization, compressing the wide dynamic range of FP32 into a mere 255 values of INT8, or even 15 values of INT4, poses a substantial challenge.
3) Ancillary Techniques
Various supplementary techniques have been developed for model quantization to address these challenges. These include scaling (per-channel or per-layer) that helps to adjust the scale and zero-point values of weight and activation tensors to fit the quantized format better.
Additionally, techniques like QAT simulate the quantization process during training to prepare a model for quantization. This simulation, or estimating the range, is facilitated through a process known as calibration. Calibration involves determining appropriate parameters or adjustments to ensure that the quantized model closely mirrors the behavior of the original, full-precision model.
Calibration processes vary based on the model type and use case, with common techniques including max, entropy, percentile, etc. Therefore, you need to explore these techniques in addition to knowing various quantization algorithms.
Importance and Need of Quantization
The primary objective of quantitative analysis in neural networks (NN) is to enhance inference speed. Due to the sheer volume of parameters involved, inferencing and training NNs are computationally intensive tasks.
For instance, an NN comprises activation functions, weights, and biases (also known as parameters), and millions of such parameters can exist within a single NN architecture.

Consider a 50-layer ResNet architecture. Such a simple model will contain approximately 26 million weights and 16 million activations, and when stored using 32-bit floating-point values, it will consume about 168 MB of memory. Performing complex arithmetic operations on such volumes of data can be extremely demanding, especially for edge devices.
With the advent of LLMs (Large Language Models), the number of parameters has escalated dramatically, leading to a substantial increase in memory footprint. As the practicality of NNs continues to rise, there is a growing necessity to deploy them on devices such as phones, laptops, and smartwatches. However, executing such complex NNs on these devices would be unfeasible without quantization.
Two main modes of model quantization exist to reduce the memory footprint of neural networks and machine learning models. We will discuss each one of them in the next section, but before that, we have a learning opportunity for you:
Modes of Quantization
Two primary machine and deep learning model quantization modes exist — PTQ and QAT. Let’s understand them both.

- PTQ
PTQ stands for Post-Training Quantization, where a pre-trained model is converted into a quantized model. Algorithms like parameter quantization and hybrid quantization are used here.
In this mode, the developer just needs the calibration data from the model to calculate clipping ranges. Once the model is calibrated, the quantized model can be obtained. Therefore, it’s a highly simple way of creating a quantized model.
- QAT
The next deep learning model quantization mode is quantization-aware training (QAT), in which the model is quantized during the training phase. Here, the 8-bit weights are learned and not converted later than in PTQ.

While PTQ can lead to a loss of model accuracy as the quantized model can differ from the original model, no such issue exists in QAT. This is because various other processes, like scaling, clipping, rounding, etc, are incorporated during model training, ensuring that the accuracy is retained after quantization.
After this introduction to quantization models, the next thing to explore is the types of quantization.
Different Types of Quantization
Quantization can be categorized into two types: uniform and non-uniform. Below, we will briefly discuss each type.

Uniform Quantization
In uniform quantization, the range of input values is divided into equally sized intervals. Here, the mapping from input to output is a linear function that ensures uniform space inputs. The linear mapping function performs a scaling and rounding operation involving a scaling factor S in its equation.
This method is simple to implement as each interval is mapped to a single quantization value. However, it is inefficient in preserving the original data’s fidelity, especially when the input distribution is not uniform.
Non-Uniform Quantization
A non-linear function maps the input and output in this quantization type, making the output not uniformly spaced for a uniform input. Therefore, the intervals can be adjusted based on the distribution of the input data.
Compared to uniform quantization, it’s a lot more flexible in mapping input values to quantization levels, helping preserve fidelity for commonly occurring values while sacrificing precision for less frequent values.
The downside is that, unlike uniform quantization, it is a bit complex and requires a sophisticated algorithm to determine the optimal quantization levels based on the input distribution.
A crucial aspect of quantization is its method. This is so because the quantization method can greatly affect how well the quantized model performs. Next, we will discuss a few key quantization methods in neural networks.
Quantization Methods in Neural Networks
You can perform quantization on NN in five broad ways. These are as follows-

1) Weight Quantization
In this method, only the weights of neural networks are quantized, and other parameters are left unquantized. Deep learning models commonly utilize 32-bit floating-point numbers to represent their weights. However, in weight quantization, the weights are often replaced with the 8-bit integers, resulting in a lower-bit representation.
Therefore, model size reduction can be achieved by representing weights through lower precision values like 8-bit integers. This happens because weights dominate the memory footprint of a deep learning model, and you can significantly reduce the model size by just quantifying the weights.
2) Activation Quantization
Activation quantization goes a step further and doesn’t limit itself to just quantizing the weights. Each layer produces activation values during the inference, and in this method, intermediate feature maps are represented with lower-precision data types, further reducing the memory requirement.
3) Parameter Quantization
Parameter quantization involves reducing the precision of a model’s weights and various other parameters like bias and other parameters depending on the model’s architecture. This inevitably leads to a decrease in accuracy but also facilitates faster processing and decreases the memory footprint of the model.
4) Dynamic Range Quantization
As the name suggests, dynamic range quantization optimizes the accuracy of a model’s weights during inference after considering the observed range of activation values. It employs varied precision levels for different layers or activations within a deep learning model.
This approach offers considerable flexibility in model optimization, offers finer control over the balance between accuracy and computational complexity, and has the potential to enhance model performance.
5) Mixed-Precision Quantization
It is a method that combines varying precision quantization techniques for quantizing weights and activations within a model, aiming to strike a balance between accuracy and efficiency.
Now that all the key aspects of model quantization have been covered, it’s time to explore today’s various quantization algorithms.
Top 7 Quantization Algorithms
Several algorithms can help you quantify your deep-learning models with varying degrees of accuracy and size reduction. Below, we will discuss a few of the key ones.

1) Integer Quantization
It’s extremely common to perform integer quantization for better deep-learning inference. The 32-bit floating point numbers in the model, typically the weights and activation outputs, are converted to the nearest 8-bit fixed-point number in this optimization strategy.
This quantization technique leads to a relatively smaller model with a higher inferencing speed. To perform integer quantization for faster deep learning inference, you must provide representative data so that the variable data (e.g., model input, model output, intermediates between layers, etc.) can be quantized. Integer quantization can be performed using various modes and methods such as QAT, Dynamic Range Quantization, etc.
2) Naïve Quantization
Naïve Quantization is an easy-to-implement integer quantization technique. In this technique, all operators are quantized to INT8 precision and calibrated using the same method.
There are a few issues and best practices you must know when using this technique, such as
- Certain architecture layers are highly sensitive to quantization, causing a significant drop in accuracy.
- INT8 is incompatible with some operator sequences and will cause the latency to worsen rather than improve.
- Certain operators like GroupConv-BN-Swish in NVIDIA’s TensorRT 8.4 can only be fused in FP16 rather than INT8. Therefore, leaving such operators in FP16 is better for maintaining accuracy and latency.
In contrast to other float point models, naive quantization can significantly decrease accuracy. This is primarily due to its lack of dynamism, as it applies the same quantization methods to all operators regardless of their susceptibility to quantization.
This limitation underscores the importance of employing more sophisticated quantization techniques, such as hybrid and selective quantization, which yield superior results in terms of accuracy and latency.
3) Float 16 Quantization
This method focuses on converting weights into 16-bit floating point values. For example, during the conversion process from TensorFlow to TensorFlow Lite’s flat buffer format, transforming weights into 16-bit floating point values leads to a 50
Certain hardware, such as GPUs, can perform computations directly in reduced-precision arithmetic, resulting in a performance boost. The Tensorflow Lite GPU delegate can be configured to leverage this technique, optimizing performance accordingly.
4) 16×8 Quantization
This technique transforms activations into 16-bit integer values and weights into 8-bit integer values during conversion. Such a conversion leads to a notable enhancement in the accuracy of the quantized model, particularly when activations are susceptible to quantization effects.
Despite this accuracy improvement, the model size can still be significantly reduced by approximately 3–4 times. Additionally, such a fully quantized model is compatible with integer-only hardware accelerators, further extending its usability.
4) K-Means Clustering
K-means Clustering (an unsupervised learning algorithm used for segmentation) can also be used for quantization. It can identify clusters of weights and activation with similar values. Here, the centroid values of each cluster are used for representation.
This method can provide higher accuracy and resolution than fixed-point quantization (for deep learning models using CNN for computer vision tasks).
5) Hybrid Quantization
Hybrid Quantization combines multiple quantization techniques to find the optimum balance between accuracy and latency (computational complexity). To be precise, it involves quantizing certain operators to INT8 precision while leaving others in their original representative data types (e.g., FP16 or FP32).
Unlike Naïve Quantization, this method is slightly more challenging to implement and requires a deep understanding of the neural model’s structure and the layers sensitive to quantization. It may even necessitate sensitivity analysis to identify such problematic layers, wherein layers are individually excluded to observe changes in accuracy and latency.
6) Selective Quantization
Selective Quantization involves converting specific parts of NN into INT8 precision, employing varying calibration methods and granularity (typically at the per tensor and channel level). Furthermore, INT8 quantization is applied to residuals, while layers sensitive to quantization, often deemed “non-friendly,” are retained in FP16 precision.
Moreover, selective quantization offers the capability to modify specific parts of the model to optimize it for quantization. This provides greater flexibility in selecting quantization parameters tailored to different types of networks, leading to improved accuracy and reduced latency.
This process is crucial despite its complexity because failing to follow it can significantly reduce accuracy in sensitive layers. Non-INT8-friendly operator sequences can increase latency, and certain blocks needing special structures for conversion with frameworks like TensorFlow may degrade performance. Thus, Selective Quantization is essential for maintaining model accuracy and optimizing performance.
While a great technique, model quantization for neural networks has pros and cons. Below, we will explore this aspect of model quantization.
Advantages and Disadvantages of Quantization
There are several advantages and disadvantages of performing model quantization that you should be aware of before you decide to give it a shot, such as
Advantages
- Faster Inference: Makes models faster to run and deploy and reduces latency, allowing their use in real-time applications such as voice recognition, autonomous vehicles, virtual reality, etc.
- Cost Effective: Smaller models make it less costly to deploy them, especially in cloud-based services.
- Better Accessibility: This enables NN to be available on various devices, platforms, and domains, helping it reach a broader audience.
- Improved Security: By reducing size, the NN can be deployed directly to the device, reducing the need to send private data to centralized servers. This increases privacy and reduces exposure to external attacks.
- Better for the Environment: Less power consumption is required to run smaller models, making cloud infrastructure and data centers more energy efficient.
- Increases Scalability: Smaller models are easier to deploy at mass due to reduced infrastructure investment.
- High Compatibility: Quantized models have higher compatibility with various hardware, making them more accessible.
Disadvantages
- Difficult to Balance: Finding the right balance between accuracy and efficiency can be difficult as aggressive model quantization for neural networks may make the model efficient but will make it significantly less effective.
- Dependence on mode: The choice of PTQ, QAT, and the neural network quantization algorithm is critical. Certain models are more apt to be quantized through certain methods, and the wrong choice can significantly hamper model accuracy.
- Retraining Time: In PTQ, the downside is that the model is retrained, which wastes time and resources in the short run.
- Precision Selection: Selecting the level of precision is crucial and difficult as low precision will lead to quality loss, while the opposite will not adequately reduce the model size.
- Difficult Calibration: Quantized models require meticulous fine-tuning and calibration to operate as expected under the precision constraints.
After understanding all these advantages and disadvantages, next, you must be aware of the tools and technologies involved with performing model quantization. Next, we will discuss the tools that can be used to perform quantization in tensorflow, pytorch, etc.
Tools and Frameworks for Large-scale Deployment
A few of the most prominent tools and frameworks commonly used for large-scale deployment of quantized models are as follows.

- PyTorch Mobile
PyTorch Mobile offers tools and libraries tailored for performing PyTorch quantization, i.e., deploying PyTorch models on mobile devices. It allows for model quantization during inference. In addition, PyTorch quantization tools enable efficient deployment of quantized models by supporting various quantization techniques like PTQ and QAT.
- TensorFlow Lite
Quantization in tensorflow can be performed using TensorFlow Lite. It is a framework designed for deploying deep learning models on mobile and other embedded devices and is considered great for on-site deployment.
TensorFlow Lite supports quantization techniques such as PTQ and QAT, making it suitable for efficiently deploying quantized models. It also provides functionalities for model conversion, optimization, and deployment.
- ONNX Runtime
ONNX Runtime is an open-source runtime engine that executes Open Neural Network Exchange (ONNX) models across different platforms. It supports various kinds of quantitation, such as INT8 quantization. This enables the efficient deployment of quantized models in various production environments.
- OpenVINO
The OpenVINO (Open Visual Inference and Neural Network Optimization) Toolkit is tailored to deploy high-performance computer vision and deep learning inference models across various hardware platforms, including CPUs, GPUs, FPGAs, and TPUs. It supports various quantization techniques, making quantized model deployment suitable on edge and IoT devices.
With the abovementioned tools, you can create an ad and employ quantized models at scale. However, there are a few considerations to take into account.
Considerations for Large-Scale Deployment
When deploying quantized models on a large scale, the following aspects must be kept in mind:
- Target Hardware Platform
Different hardware platforms provide varying capabilities for model quantization and often support certain data types and precision. Therefore, it is necessary to examine the capabilities and constraints the target hardware provides, such as CPU, GPU, TPU, etc., and create a custom neural network quantization approach.
- Accuracy vs. Efficiency Tradeoff
As you know, a major aspect of quantization is managing the accuracy and efficiency tradeoff. Therefore, when deploying quantized models on a large scale, you must consider the accuracy and efficiency requirements of the target product or service. You can deploy techniques like QAT, per-channel scaling, and a few calibration techniques to minimize accuracy loss and maximize efficiency.
- Complexity of Quantization Techniques
Quantization is a complex technique that simplifies other complex deep learning algorithms. Therefore, you must assess the need for quantization and the level of quantization required based on the data distribution, model architecture, and deployment nature. Thus, it would help to opt for a minimally complex quantization technique that gives you the best results without creating a complicated deep-learning pipeline.
Several examples of large-scale deployment of quantized models exist worldwide. Next, we will explore the prominent industries where quantized models have found great use.
Industry Applications: Real-World Examples
Several industries have benefited from model quantization. The key industries that have found applications for quantized models include-

- Healthcare
Model quantization enables the deployment of medical imaging solutions on edge devices like portable ultrasound machines, transforming them into AI-powered tools. This advancement helps detect and diagnose heart conditions while reducing costs by minimizing the need for expensive, bulky, specialized equipment.
- NLP
Quantized models have enabled complex NLP-based AI models to be deployed in devices with limited hardware resources, such as watches and speakers. This has allowed for the creation of chatbots and various smart devices that can communicate with users in natural language.
- Autonomous Vehicles
Autonomous vehicles need to run AI models in real time. To run AI algorithms efficiently in embedded devices, model quantization has played a crucial role. Quantized models have increased responsiveness, safety, and better decision-making of autonomous driving vehicles.
- Industrial Automation
Edge devices can now monitor machinery, automate routine tasks, and find defects before they occur. This helps reduce downtime and makes industries more profitable. These devices have limited computation capability but can run AI through quantization.
- Retail and E-commerce
Quantized models enhance customer engagement and improve inventory management. Deploying the optimized AI algorithm, in-store cameras track available products and recommend products to customers on the e-commerce website.
Conclusion
Quantization has proven to be a great solution for AI, especially generative AI. It has helped developers reduce the size of their deep NN, which means faster inference and more energy efficiency. Real-time applications have particularly benefited from quantized AI algorithms.
To ensure your quantized model maintains its quality, try QAT, carefully select a precision level, calibrate for effective performance under precision constraints, and ensure thorough testing and validation. Constant monitoring and fine-tuning of quantized models are also key to their success.
FAQs
- What is the difference between quantization-aware training (QAT) and post-training quantization (PTQ)?
The QAT model performs quantization during training, ensuring the model learns to accommodate quantization effects. PTQ, on the contrary, performs quantization once the model is trained, which can cause a drop in model accuracy.
QAT is more accurate but requires more time and computational resources. In contrast, PTQ is easier to implement and faster to train but requires performing various calibration techniques to restrict accuracy loss.
- How much accuracy loss can be expected from model quantization?
The degree of accuracy loss from model quantization depends on several factors, including model architecture, dataset, quantization method, and the algorithm employed. Typically, quantizing from 32-bit floating-point precision (FP32) to 8-bit integer precision (INT8) can lead to accuracy reductions ranging from 1
- Can model quantization improve the accuracy of a neural network?
Yes, it is possible, especially in QAT. The neural network’s forward and backward passes utilize low-precision weights in a quantized model developed through QAT. During training, the loss function accommodates and adjusts for errors from low-precision calculations, making the model robust to quantization effects.
Consequently, the model achieves higher accuracy during real-world inference because it has been trained to recognize and effectively compensate for quantization effects.
- What different quantization levels are used?
Several quantization levels with lower levels lead to a higher compression and accuracy loss.
Common quantization levels are-
FP32 (32-bit Floating Point, aka Single Precision) is the standard floating point format of deep NN. It provides good accuracy but requires a lot of resources.
FP16 (6-bit Floating Point, aka Half Precision) uses 50
8-bit Integer: Typically used for quantization, it reduces memory footprint by representing model parameters using only 8 bits.
4-bit Integer: This is used for specialized hardware with limited power. It represents parameters with just 4 bits, leading to greater compression but significant memory loss.
- How does model quantization impact inference speed?
Model quantization reduces the model’s computational complexity, arithmetic operations, and memory bandwidth requirements, thereby increasing inference speed. Thus, a quantized model is more optimized for hardware, enabling faster execution of them.
- Is model quantization suitable for all types of neural networks?
No. Several factors affect the suitability of quantization. Network architecture is the primary one, with deep learning algorithms like CNN being more friendly to quantization than RNN. Model quantization is also unsuitable for NN, where accuracy is paramount and deployment constraints are not.
- What tools and frameworks are available for model quantization?
Several tools and frameworks have features for model quantization. These include-
- TensorFlow Lite
- PyTorch Mobile
- ONNX
- NVIDIA TensorRT
- Intel OpenVINO Toolkit
- TFLite Model Optimization Toolkit
- CMSIS-NN
- How do I calibrate a quantized model?
The easiest way is to quantize your pre-trained model using the PQT method and algorithms such as weight quantization and activation quantization.
- Can quantization be applied to other parts of a deep learning pipeline besides the model?
Quantization can be used in various parts of neural networks and machine learning pipelines. Processes where quantization can be useful and can make the overall process of model development more streamlined and optimized include-
- Data Preprocessing
- Feature Engineering and Normalization
- Output post-processing
- Compression and Pruning
- What are the security implications of deploying quantized models?
While model quantization helps increase security and privacy, as less data needs to be sent from edge devices to centralized servers, there are a few concerns. Internal representations of a quantized model are easier to leak, making them more vulnerable to inversion attacks. Also, quantized models are easier to steal and simpler to reverse engineer, causing adversaries to find and exploit loopholes.
We hope this article made you more aware of model quantization in deep learning. Contact us to learn AI and model development in this field.