Here’s the human-written answer for how ChatGPT works. ChatGPT has been a household name for less than two years, so it’s no surprise that lots of people are still unsure how it works. If I didn’t have to write about it so much, I probably would be too. So let’s dial things back: to understand how ChatGPT works, we need to start by talking about the underlying language engine that powers it.
The GPT bit of ChatGPT stands for Generative Pre-trained Transformer. It’s made up of a family of AI models, including GPT-4, GPT-4o, and most recently, GPT-4o mini. GPT-4o and GPT-4o mini are a little different because they’re multimodal, which means they can work with text, images, and audio—but we’ll get to that a little later.
The GPT models were developed by OpenAI (the company behind ChatGPT and the image generator DALL·E 3), but they power everything from Bing’s AI features to writing tools like Jasper and Copy.ai. In fact, many of the AI text generators available at the moment use GPT models, as well as similar models from other companies—though they tend to keep quiet when they use each one.
ChatGPT brought GPT into the limelight because it made the process of interacting with an AI text generator simple and—most importantly—free to everyone. Plus, it’s a chatbot, and people have loved a good chatbot since SmarterChild.
While GPT is the most prominent large language model (LLM) right now, there are now plenty of others. Google has its Gemini models and chatbot; Anthropic has Claude; Meta has Llama 3, which powers its Meta AI chatbot. And that’s before you dive into the models aimed at large companies, like Writer’s Palmyra LLMs, or open models like Mixtral 8x22B. Still, at least for now, OpenAI’s offerings are still the most powerful widely available and the de facto industry standard.
So the answer to “how does ChatGPT work?” is basically: GPT. But let’s dig a little deeper.
Table of contents:
- What is ChatGPT?
- How does ChatGPT work?
- Supervised vs. unsupervised learning
- Transformer architecture
- Tokens
- Reinforcement learning from human feedback (RLHF)
- Natural language processing (NLP)
- Multimodality in ChatGPT
- What is the ChatGPT API?
- What’s next for ChatGPT?
What is ChatGPT?
ChatGPT is an app built by OpenAI. Using the GPT AI models, it can answer your questions, write copy, generate images, draft emails, hold a conversation, brainstorm ideas, explain code in different programming languages, translate natural language to code, and more—or at least try to—all based on the natural language prompts you feed it. It’s a chatbot, but a really, really good one.

Need any IT Device Shop Here Coupon Code link:
Image from ChatGPT
The latest version of ChatGPT is also multimodal, at least if you use the GPT-4o or GPT-4o mini model. In addition to text prompts, it can respond to images and audio. This opens up a wide range of real-world uses, like translating a conversation in real time or helping you identify a restaurant dish from a photo.
Note: GPT-4o mini can’t yet support all the same inputs and outputs as GPT-4o—for example, video and audio—but OpenAI says it plans to roll that out in the future.
Since it launched at the end of 2022, ChatGPT has gotten a lot more powerful and useful. It can search the web to find answers to your prompts, interact with other apps through custom GPTs (what OpenAI calls its extension framework), and create images using the DALL·E 3 image model.
Of course, ChatGPT is also a way for OpenAI to get a lot of real-world data on how its models perform from actual users and serves as a fancy demo for the power of GPT, which could otherwise feel a little fuzzy unless you were deep into machine learning.
One of ChatGPT’s biggest features is that it can remember all the context from the conversation you’re having with it. If you tell it something in your initial prompt, it can recall it much later in the conversation. You’re also able to ask it to rework things and correct any mistakes. It makes interacting with the AI feel like a genuine back-and-forth.
If you want to really get a feel for it, go and spend five minutes playing with ChatGPT now (it’s free!), and then come back to read about how it works.
How does ChatGPT work?
This humongous dataset was used to form a deep learning neural network […] modeled after the human brain—which allowed ChatGPT to learn patterns and relationships in the text data […] predicting what text should come next in any given sentence.
ChatGPT works by attempting to understand your prompt and then spitting out strings of words that it predicts will best answer your question, based on the data it was trained on. While that might sound relatively simple, it belies the complexity of what’s going on under the hood.
Supervised vs. unsupervised learning
Let’s actually talk about that training. The P in GPT stands for “pre-trained,” and it’s a super important part of why GPT is able to do what it can do.
Before GPT, the best performing AI models used “supervised learning” to develop their underlying algorithms. They were trained with manually-labeled data, like a database with photos of different animals paired with a text description of each animal written by humans. These kinds of training data, while effective in some circumstances, are incredibly expensive to produce. Even now, there just isn’t that much data suitably labeled and categorized to be used to train LLMs.
Instead, GPT employed generative pre-training, where it was given a few ground rules and then fed vast amounts of unlabeled data—near enough the entire open internet. It was then left “unsupervised” to crunch through all this data and develop its own understanding of the rules and relationships that govern text.
GPT-4o was seemingly trained in the same way, though in addition to text, its training data also included images and audio. This way, it could learn not only what an apple was, but what one looks like too.
Of course, you don’t really know what you’re going to get when you use unsupervised learning, so GPT is also “fine-tuned” to make its behavior more predictable and appropriate. There are a few ways this is done (which I’ll get to), but it often uses forms of supervised learning.
Transformer architecture
All this training is intended to create a deep learning neural network—a complex, many-layered, weighted algorithm modeled after the human brain—which allowed ChatGPT to learn patterns and relationships in the text data and tap into the ability to create human-like responses by predicting what text should come next in any given sentence.
This network uses something called transformer architecture (the T in GPT) and was proposed in a research paper back in 2017. It’s absolutely essential to the current boom in AI models.
While it sounds—and is—complicated when you explain it, the transformer model fundamentally simplified how AI algorithms were designed. It allows for the computations to be parallelized (or done at the same time), which means significantly reduced training times. Not only did it make AI models better, but it made them quicker and cheaper to produce.
At the core of transformers is a process called “self-attention.” Older recurrent neural networks (RNNs) read text from left-to-right. This is fine when related words and concepts are beside each other, but it makes things complicated when they’re at opposite ends of the sentence. (It’s also a slow way to compute things as it has to be done sequentially.)
Transformers, however, read every word in a sentence at once and compare each word to all the others. This allows them to direct their “attention” to the most relevant words, no matter where they are in the sentence. And it can be done in parallel on modern computing hardware.
Of course, this is all vastly simplifying things. Transformers don’t work with words: they work with “tokens,” which are chunks of text or an image encoded as a vector (a number with position and direction). The closer two token-vectors are in space, the more related they are. Similarly, attention is encoded as a vector, which allows transformer-based neural networks to remember important information from earlier in a paragraph.
And that’s before we even get into the underlying math of how this works. While it’s beyond the scope of this article to get into it, Machine Learning Mastery has a few explainers that dive into the technical side of things.
Tokens
How text is understood by AI models is also important, so let’s look a little deeper at tokens. GPT-3, the original model behind ChatGPT, was trained on roughly 500 billion tokens, which allows its language models to more easily assign meaning and predict plausible follow-on text by mapping them in vector-space. Many words map to single tokens, though longer or more complex words often break down into multiple tokens. On average, tokens are roughly four characters long. OpenAI has stayed quiet about the inner workings of GPT-4 and GPT-4o, but we can safely assume it was trained on much the same dataset since it’s even more powerful.

Need any IT Device Shop Here Coupon Code link:
All the text tokens came from a massive corpus of data written by humans, at least for GPT-3. That includes books, articles, and other documents across all different topics, styles, and genres—and an unbelievable amount of content scraped from the open internet. Basically, it was allowed to crunch through the sum total of human knowledge to develop the network it uses to generate text.
Now, researchers are running out of human-created training data, so GPT-4 and later models may also be trained on synthetic—or AI-created—training data.
Based on all that training, GPT-3’s neural network has 175 billion parameters or variables that allow it to take an input—your prompt—and then, based on the values and weightings it gives to the different parameters (and a small amount of randomness), output whatever it thinks best matches your request. OpenAI hasn’t said how many parameters GPT-4 has, but it’s a safe guess that it’s more than 175 billion and less than the once-rumored 100 trillion parameters. Regardless of the exact number, more parameters doesn’t automatically mean better. Some of GPT-4’s increased power probably comes from having more parameters than GPT-3, but a lot is probably down to improvements in how it was trained.
GPT-4o and GPT-4o mini are even harder to draw conclusions about. In addition to text, they were trained on images and audio—which can also be broken down into discrete tokens—so their neural networks must have billions of additional parameters to deal with those additional modalities. Unfortunately, the corporate competition between the different AI companies means that their researchers are now unable or unwilling to share all the interesting details about how their models were developed.
Reinforcement learning from human feedback (RLHF)
Of course, GPT’s initial neural network was entirely unsuitable for public release. It was trained on the open internet with almost no guidance, after all. So, to further refine ChatGPT’s ability to respond to a variety of different prompts in a safe, sensible, and coherent way, it was optimized for dialogue with a technique called reinforcement learning with human feedback (RLHF).
Essentially, OpenAI created some demonstration data that showed the neural network how it should respond in typical situations. From that, they created a reward model with comparison data (where two or more model responses were ranked by AI trainers) so the AI could learn which was the best response in any given situation. While not pure supervised learning, RLHF allows networks like GPT to be fine-tuned effectively.

Image from ChatGPT
This process has continued with each subsequent release of GPT and is part of what has allowed the later models like GPT-4 and GPT-4o to be safer and more reliable.
Natural language processing (NLP)
All this effort is intended to make GPT as effective as possible at natural language processing (NLP). NLP is a huge bucket category that encompasses many aspects of artificial intelligence, including speech recognition, machine translation, and chatbots, but it can be understood as the process through which Al is taught to understand the rules and syntax of language, programmed to develop complex algorithms to represent those rules, and then made to use those algorithms to carry out specific tasks.
Since I’ve covered the training and algorithm development side of things, let’s look at how NLP enables GPT to carry out certain tasks—in particular, responding to user prompts.
It’s important to understand that for all this discussion of tokens, ChatGPT is generating text of what words, sentences, and even paragraphs or stanzas could follow. It’s not the predictive text on your phone bluntly guessing the next word; it’s attempting to create fully coherent responses to any prompt. This is what transformers bring to NLP.
In the end, the simplest way to imagine it is like one of those “finish the sentence” games you played as a kid.
In the end, the simplest way to imagine it is like one of those “finish the sentence” games you played as a kid. ChatGPT starts by taking your prompt, breaking it down into tokens, and then using its transformer-based neural network to try to understand what the most salient parts of it are, and what you are really asking it to do. From there, the neural network kicks into gear again and generates an appropriate output sequence of tokens, relying on what it learned from its training data and fine-tuning.
Multimodality in ChatGPT: Images, audio, and more

Need any IT Device Shop Here Coupon Code link:
While natural language processing is a huge part of ChatGPT, over the past year, the chatbot has become increasingly multimodal. That means that, using GPT-4o (and soon, GPT-4o mini), ChatGPT can also understand images and audio as part of the same prompt.
If you’re thinking “couldn’t ChatGPT do that before?” you’re kind of right. The crux is how it happens.
Before GPT-4o, ChatGPT was able to understand images using a separate AI model that created a text description of the image. Similarly, it could “listen” to audio input, but what was really happening was a speech-to-text AI model was converting the spoken words to text. In both cases, the text was what was passed to GPT, which then responded with text or, in some cases, by prompting DALL·E 3 to create an image.
With GPT-4o, the same AI model is able to both understand the text, audio, and image inputs and output a response using text, audio, or images. It’s a big step forward.
Spitting out words, not knowledge
For all my talk of “understanding” and “comprehending,” you have to remember that these are simply the most useful words we have for describing how AIs operate. GPT doesn’t truly understand English, but it has a very detailed map of how many concepts relate to each other. The makers of ChatGPT are the first to say that it can produce incorrect (and possibly harmful) information, though they’re working hard to fix it.
Here’s a tame example. When I asked ChatGPT using GPT-3 and GPT-4 to reply to “Harry Guinness is…” GPT-3 first replied by asking which Harry Guinness. Great question—there are literally two of us! So I said, “Harry Guinness the writer” (that’s me). GPT-4 guessed who I was straight away, though both responses were fascinating:
GPT-3: Harry Guinness is a freelance writer and journalist based in Ireland. He has written for a variety of publications, including The New York Times, The Guardian, The Huffington Post, and Popular Mechanics. He covers topics ranging from technology and photography to travel and culture.
GPT-4: Harry Guinness is an Irish writer, photographer, and technology expert. He has written for various publications, including How-To Geek, Lifehacker, and Tuts+. His work primarily focuses on technology, tutorials, and tips, as well as photography and image editing. Guinness has built a reputation for creating detailed guides that help readers understand complex subjects or solve problems in a straightforward manner.
GPT-3’s first and last lines are pulled almost verbatim from my various websites and author bios around the web (although I normally list myself as a freelance writer and photographer, not a journalist). But the list of publications is basically made up. I’ve written for The New York Times, but not for The Guardian, The Huffington Post, or Popular Mechanics (I do write regularly for Popular Science, so that might be where that came from).
GPT-4 gets the photographer part right and actually lists some publications I’ve written for, which is impressive, though they’re not the ones I’d be most proud of. It’s a great example of how OpenAI has been able to increase the accuracy of GPT-4 relative to GPT-3, though it might not always offer the most correct answer.
But let’s go back to GPT-3 as its error provides an interesting example of what’s going on behind the scenes in ChatGPT. It doesn’t actually know anything about me. It’s not even copy/pasting from the internet and trusting the source of the information. Instead, it’s simply predicting a string of words that will come next based on the billions of data points it has.
For example: The New York Times is grouped far more often with The Guardian and The Huffington Post than it is with the places I’ve written for, like Wired, Outside, The Irish Times, and, of course, Zapier. So when it has to work out what should follow on from The New York Times, it doesn’t pull from the published information about me; it pulls that list of large publications from all the training data it has (or really, considers where they’re mapped in vector space). It’s very clever and looks plausible, but it isn’t true.
GPT-4 does a much better job and nails the publications, but the rest of what it says really just feels like plausible follow-on sentences. I don’t think it has any great appreciation for my reputation: it’s just saying the kind of thing a bio says. It’s far better at hiding how it works than GPT-3, though it’s actually using much the same technique.
I’ve tested this with GPT-4o, too, and the results are much the same. Though ChatGPT can now search the web—at least if you’re a ChatGPT Plus subscriber—which means it can find more up-to-date and accurate information rather than just relying on its training data.
What is the ChatGPT API?
OpenAI doesn’t have a just-us attitude with its technology. The company has an API platform that allows developers to integrate the power of ChatGPT into their own apps and services (for a price, of course).
What’s next for ChatGPT?
ChatGPT has gone from a novelty to an increasingly useful productivity tool over the past year. It’s clear that multimodality is going to be the next big feature for chatbots and AI models, so expect it to get increasingly good at responding to image, audio, and maybe even things like video prompts.
Right now, GPT-4o is pretty bad at generating images, so ChatGPT tends to use DALL·E 3. Maybe the next version will have a more powerful image generator built into the base model.
Otherwise, OpenAI is already training the next version of GPT. We’ll have to wait and see what features that brings to ChatGPT.
How Was ChatGPT Trained?
OpenAI’s team trained ChatGPT to be as conversational and “knowledgeable” as it is today.
Here’s a detailed walkthrough of the ChatGPT development journey to help you understand how and why it works so well.
Training Data
To give relevant answers, LLMs need information. They use information known as training data; a giant text bank from millions of sources on a wide variety of topics.
Compiling this training data is the first step in developing a model like ChatGPT.
This giant collection of text is where the model learns language, grammar, and contextual relationships. And it’s crucial in the training process.
GPT-3’s training data came from five existing datasets:
- Common Crawl: A collection of text pulled from billions of web pages containing trillions of words. OpenAI filtered it for high-quality reference material only.
- WebText2: OpenAI created this dataset (a extended version of the original WebText) by crawling Reddit and websites it links to
- Books1 and Books2: Two internet-based collections of text from unspecified published books (likely from diverse genres and eras)
- Wikipedia: A complete crawl of the raw text from every page of the English-language Wikipedia.
- Persona-Chat: OpenAI’s own dataset that comprises over 160,000 dialogues between participants with unique personas
Persona-Chat is used to train conversational AI. It was likely used to fine-tuneGPT-3.5 to work better in a chatbot format.
Tokenization
Before it’s processed by an LLM, training data is tokenized. This involves breaking the text down into bite-sized chunks called tokens. These can be words, parts of words, or even characters.

Need any IT Device Shop Here Coupon Code link:
Converting raw text data into these tokens allows the LLM to analyze it more easily.
OpenAI used a form of tokenization called byte pair encoding (BPE) for GPT-3. This fancy term just means the system can create sub-word tokens as small as one character. It also creates tokens to represent concepts like the start and end of a sentence.
Each token is assigned a unique integer (a whole number) at the end of the tokenization process. This allows the model’s neural network to process them more efficiently. (We’ll explain neural networks in more detail soon.)
After tokenization, the datasets used to train GPT-3 were:
Weight in training mix is the proportion of examples the system took from each dataset. Assigning different weights allows the model to learn from the most important or relevant information.
Neural Network Development
A neural network is a computer program that emulates the structure of the human brain. ChatGPT uses an especially sophisticated type known as a transformer model.
Transformer models can analyze more text simultaneously than traditional neural networks. That means they’re better at figuring out how each token relates to other tokens. In other words, it analyzes how context plays a part in the meaning of a word or phrase.
For example, “break a leg” can mean to fracture a bone. Or it can mean “good luck” in a theater setting. Context helps the system understand which meaning is more likely.
Neural networks are a crucial component in any LLM. The algorithms they use are foundational to the training process and responsible for processing and generating text.
OpenAI’s complex transformer model revolutionized the NLP field.
But first, it had to learn the parameters for carrying out these tasks.
Pre-Training
To understand the information its trainers feed it, the neural network completes what’s called pre-training.
It analyzes every token in the dataset one by one. Then identifies patterns and relationships to predict missing words from text samples.
Here’s how ChatGPT describes it:

A typical pre-training task is to predict the next word in a sequence. With the full training dataset as context, the model can apply patterns it’s learned in the task.
For example, it might learn that the word “going” is often followed by “to.” Or that “thank” is followed typically by “you.”
Humans don’t learn every new process from scratch. As we grow, we rely on previous experience or knowledge to help us understand and complete new tasks. ChatGPT’s technology works in a similar way.
It records these patterns and stores them as parameters (data points). Then it can refer to them to make further predictions or solve problems.
At the end of the pre-training process, OpenAI said ChatGPT had developed 175 billion parameters. And this huge amount of data means more options for the system to pull from for an accurate response.
Reinforcement Learning From Human Feedback (RLHF)
LLMs are generally functional after pre-training. But ChatGPT also went through another pioneering OpenAI process called Reinforcement Learning from Human Feedback (RLHF).
This worked in two stages:
- The developers gave the system specific tasks to complete (e.g., answering questions or generating creative work)
- Humans rated the LLM’s response for effectiveness and fed these ratings back into the model so it understood its performance
RLHF’s fine-tuning made ChatGPT more effective at generating relevant, useful responses every time.
This development process also gives the system a huge knowledge base and helps it respond with sophistication to diverse prompts.
RLHF’s extra coaching involved three additional rounds:
1. Supervised Fine-Tuning (SFT)
The first round of RLHF involved feeding the GPT-3 model prompts with human-written responses. This supervised fine-tuning (SFT) developed its understanding of what an effective response looks like.
Here’s how SFT works:

Need any IT Device Shop Here Coupon Code link:
Image Source borrowed from: Medium by dadynews.com
OpenAI hired 40 contractors to create a custom supervised training dataset. They started by choosing real user prompts from the OpenAI application programming interface (API). Then supplemented them with new ones.
Contractors then wrote appropriate responses for each prompt. This created a known output for each input, or a correct answer for each query.
The team created 13,000 of these input/output pairs and fed them into the GPT-3 model.
The model then compared its own generated response with the contractors’ guide responses. By highlighting differences between the two, the model learned to adapt and generate more effective replies.
2. Reward Model
The next step of training expanded on the SFT process by integrating a reward system.
It used human participants to assess and rank multiple responses to a query to further train the model for effectiveness.
Here’s how the reward model works:

Image Source borrowed from: Medium by dadynews.com
The updated model generated between four and nine responses for each set of prompts. Human contractors known as labelers ranked these responses from best to worst.
They presented this data to the model with the original query to help it understand how effective each of its responses was.
This ranking system trained the model to maximize its “reward” by generating more responses similar to the ones that received the highest ranking score.
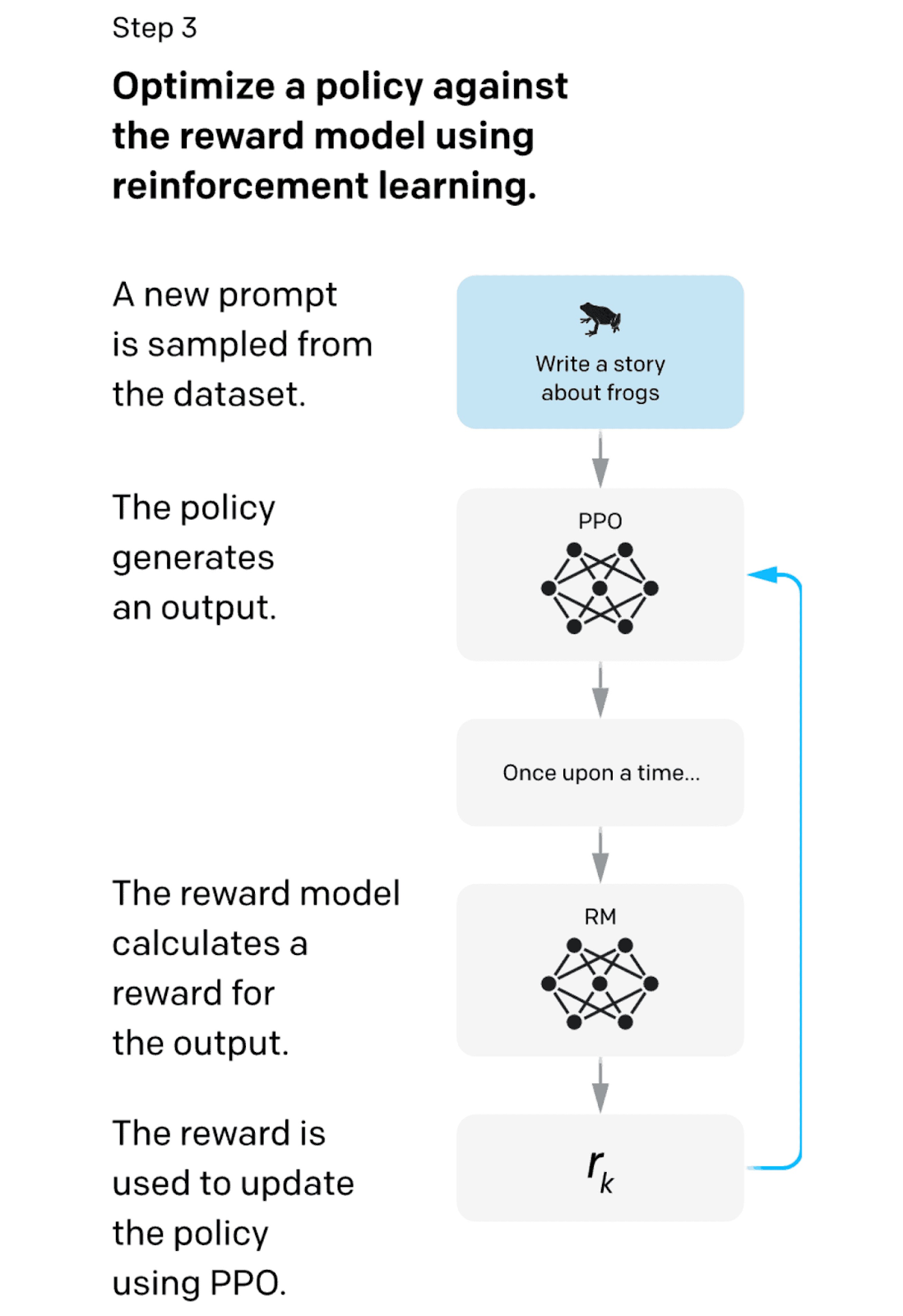
3. Reinforcement Learning
The final stage of the RLHF process refined the model’s behavior based on prior training.
Here’s how this reinforcement learning works:
Need any IT Device Shop Here Coupon Code link:
Image Source borrowed from: Medium by dadynews.com
The system takes a random customer prompt and generates a response using the policies taught in the reward model. Each prompt/response pair received a reward value, which was then fed back into the model.
Repeating this supervised learning process allowed the model to evolve its policy. Because the more you practice something, the better you get at it.
A mechanism called Proximal Policy Optimization (PPO) ensured the model didn’t over-optimize itself.
PPO is a type of reinforcement learning technique called a policy gradient method. This family of algorithms works in three stages:
- Sample an action (in this case, a prompt)
- Observe the value of the reward
- Tweak the policy
PPO is easy to implement and performs well. It is now OpenAI’s go-to method for reinforcement learning across the board.
What’s the Difference Between ChatGPT and a Search Engine?
ChatGPT is a conversational AI chatbot that responds to prompts dynamically. A search engine is a searchable index of user-generated information.
ChatGPT gets compared to search engines because of the similarities in how people use the two technologies in the real world. But there are vast differences in both their mechanisms and optimal use cases.
Understanding the differences between these two technologies helps determine their best use cases.
For a simple search, ChatGPT will generate a single, concise answer. However, the response won’t have a specific source. It will also be limited to the LLM’s interpretation of what constitutes a good answer, and the answer may be incorrect.

Searching the same query on Google returns more in-depth information.

The answer appears immediately at the top of the page. And is supplemented by a summary from Wikipedia, additional queries users tend to search, and web pages that provide more information.
More complex searches also generate different results.
For the query, “difference between ChatGPT and a search engine,” ChatGPT provides a numbered list of differences followed by a summary.

Google’s response is more limited. There’s a small featured snippet sourced from the top-ranking webpage with a summary of the answer. More information is available, but requires users to click on a link.

Need any IT Device Shop Here Coupon Code link:
The biggest difference in functionality is that users can follow up on ChatGPT’s responses conversationally. Asking another question generates a new response guided by the context of the previous information.

Searching a new query on Google returns entirely new results. However, Google uses past searches to help guide your journey.
Let’s say you search for “pumpkin pie.” If you then type in “how to,” Google offers helpful predictions like “how to make pumpkin pie” and “how to make pumpkin pie spice.”

Need any IT Device Shop Here Coupon Code link:
ChatGPT is also capable of other diverse tasks that search engine technology can’t replicate. For example, you can ask it to generate creative works.

Need any IT Device Shop Here Coupon Code link:
However, you should always check these answers for inaccuracies.
The same query searched through Google can only return existing creative material.

Here are some other differences between ChatGPT and search engines:
| Feature | ChatGPT | Search Engines |
| Purpose | To respond to user queries directly | To provide relevant web results that answer user queries |
| Interaction type | Conversational inputs and outputs, creating a chatbot experience | Single text-based queries to look up information |
| Output type | Dynamically generated responses | A list of relevant indexed web pages |
| Output scope | Relies on knowledge acquired through the training process | Access to the full breadth of indexed web pages |
| Contextual awareness | Retains knowledge of the preceding conversation for contextual continuity | Offers some contextual continuity within predictions |
| Task suitability | Adaptable to diverse tasks, from information gathering to creative content generation | Primarily focused on information retrieval |
| Currency | Outputs limited by the recency of the latest training data | Offers up-to-date, realtime web results |
| Limitations | Can suffer from biases or inaccuracies inherent in the training data | Relies on the accuracy of user-generated content on web pages |
What Can ChatGPT Do?
ChatGPT can respond to a huge and diverse range of prompts with useful, relevant text. However, always be aware of its potential to provide inaccurate answers.
You can use ChatGPT to:
- Answer questions
- Summarize concepts
- Generate ideas
- Write tailored messages and emails
- Develop creative works
- Proofread writing
- Check code for errors
- Translate other languages
Let’s look at a few of these in more detail.
Answer Questions
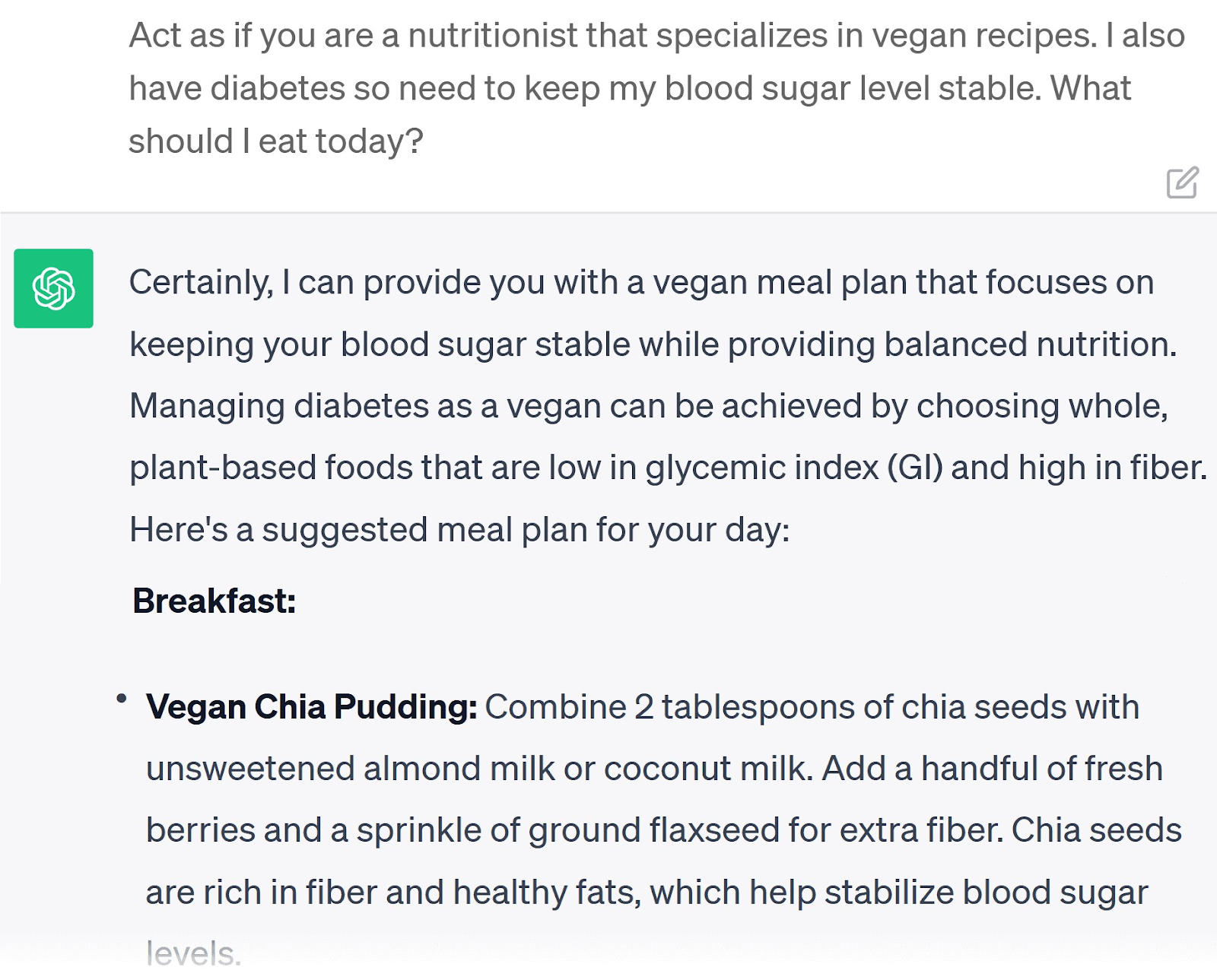
ChatGPT will answer questions with generic advice. For example, “What should I eat today?”

Want to take it to the next level? Give it some guidance.
Start questions with “act as” and suggest a profession. This can help ChatGPT draw on more contextual training data to answer.
For example, we started with “Act as if you are a nutritionist” and added some more detail. Here’s part of the answer it gave:
Need any IT Device Shop Here Coupon Code link:
If you want even more personalized answers, invite ChatGPT to request more information.
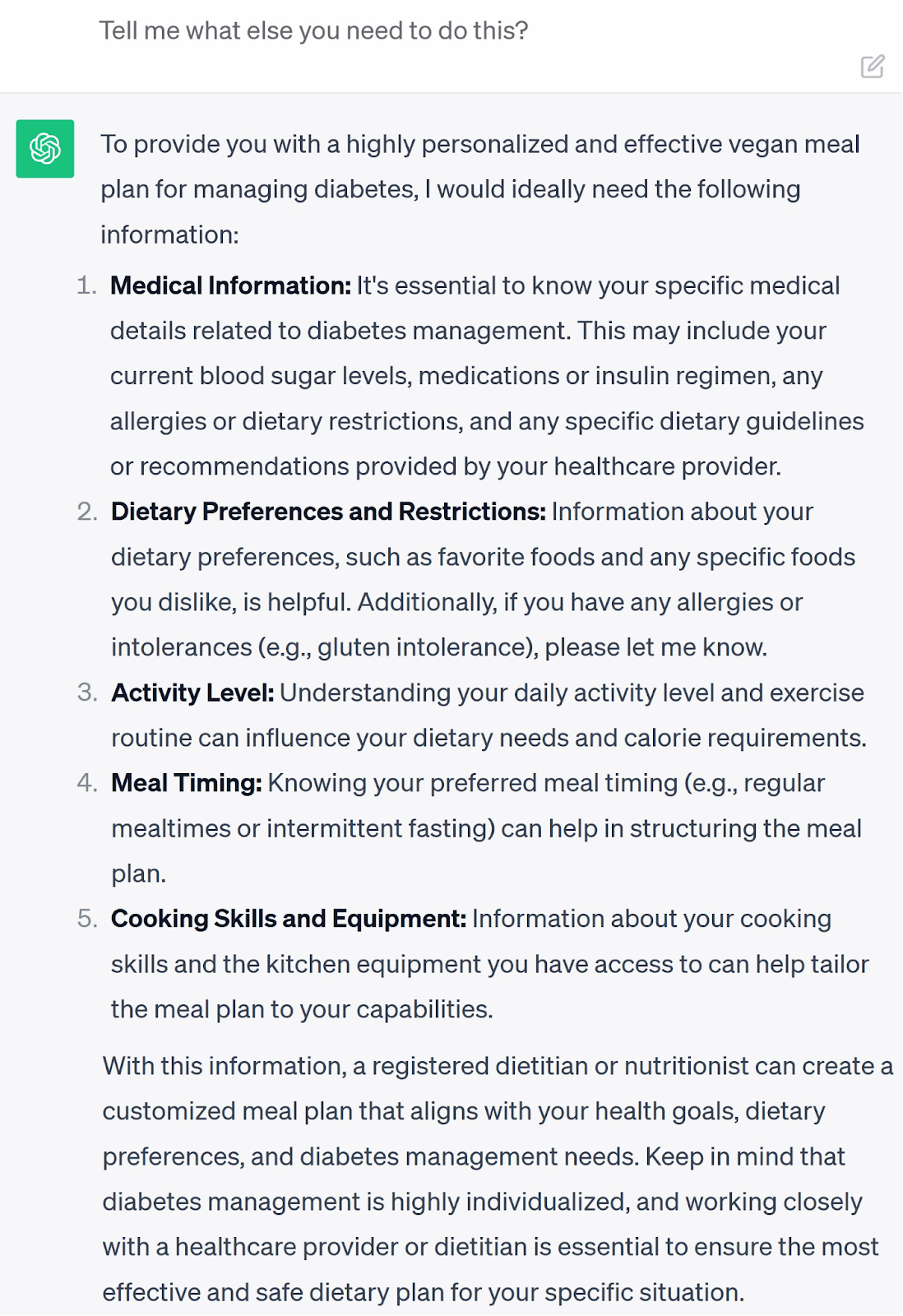
If it makes a mistake, point it out. This will help improve the accuracy of results over time.
Write Tailored Messages and Emails
Ask ChatGPT to write a cold direct message and it’ll sound generic and robotic.
Like so:

Add the words “concise” and “friendly” and it starts to sound more like a human:

Add in more detail (e.g., demographic) and you’ll get an even more tailored response:

Fill in the gaps ChatGPT doesn’t know (what it puts in square brackets) to focus it further:

Finish with specifics about the person you’re targeting. And you’ll have a personalized DM in a fraction of the time it usually takes.
Check Code for Errors
Unlike complex debugging tools, you can use ChatGPT to identify and fix your code.
Paste the code into the chat box and ask where the error is:

Need any IT Device Shop Here Coupon Code link:
Need more explanation? Prompt, “Explain in detail why it’s wrong.”
ChatGPT will break down each line, where the error is, and why it’s incorrect.

Need any IT Device Shop Here Coupon Code link:
Because you know the system can get things wrong, you can also ask for test cases to check its work.
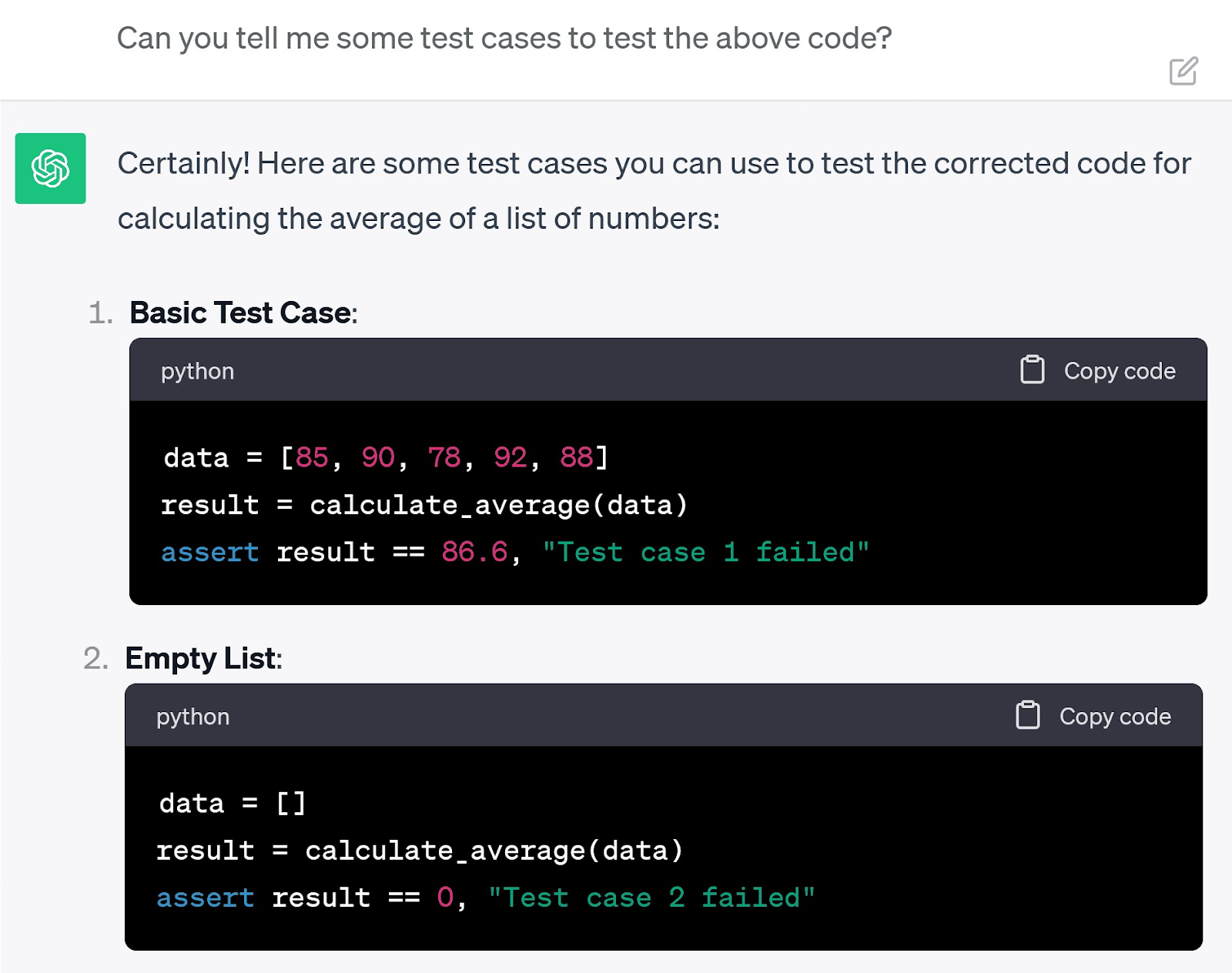
This allows you to ensure the program runs properly with the new code. And gives you confidence when applying ChatGPT’s suggestions.
Need any IT Device Shop Here Coupon Code link: