Vision Transformers (ViT), since their introduction by Dosovitskiy et. al. [reference] in 2020, have dominated the field of Computer Vision, obtaining state-of-the-art performance in image classification first, and later on in other tasks as well.
However, unlike other architectures, they are a bit harder to grasp, particularly if you are not already familiar with the Transformer model used in Natural Language Processing (NLP).
If you are into Computer Vision (CV) and are still unfamiliar with the ViT model, don’t worry! So was I!
In this brief piece of text, I will show you how I implemented my first ViT from scratch (using PyTorch), and I will guide you through some debugging that will help you better visualize what exactly happens in a ViT.
While this article is specific to ViT, the concepts you will find here, such as the Multi-headed Self Attention (MSA) block, are present and currently very relevant in various sub-fields of AI, such as CV, NLP, etc…
Defining the task
Since the goal is just learning more about the ViT architecture, it is wise to pick an easy and well-known task and dataset. In our case, the task is the image classification for the popular MNIST dataset by the great LeCun et. al. [reference].
If you didn’t already know, MNIST is a dataset of hand-written digits ([0–9]) all contained in 28×28 binary pixels images. The task is referred to as trivial for today’s algorithms, so we can expect that a correct implementation will perform well.
Let’s start with the imports then:
import numpy as np
from tqdm import tqdm, trange
import torch
import torch.nn as nn
from torch.optim import Adam
from torch.nn import CrossEntropyLoss
from torch.utils.data import DataLoader
from torchvision.transforms import ToTensor
from torchvision.datasets.mnist import MNIST
np.random.seed(0)
torch.manual_seed(0)
Let’s create a main function that prepares the MNIST dataset, instantiates a model, and trains it for 5 epochs. After that, the loss and accuracy are measured on the test set.
def main():
# Loading data
transform = ToTensor()
train_set = MNIST(root='./../datasets', train=True, download=True, transform=transform)
test_set = MNIST(root='./../datasets', train=False, download=True, transform=transform)
train_loader = DataLoader(train_set, shuffle=True, batch_size=128)
test_loader = DataLoader(test_set, shuffle=False, batch_size=128)
# Defining model and training options
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using device: ", device, f"({torch.cuda.get_device_name(device)})" if torch.cuda.is_available() else "")
model = MyViT((1, 28, 28), n_patches=7, n_blocks=2, hidden_d=8, n_heads=2, out_d=10).to(device)
N_EPOCHS = 5
LR = 0.005
# Training loop
optimizer = Adam(model.parameters(), lr=LR)
criterion = CrossEntropyLoss()
for epoch in trange(N_EPOCHS, desc="Training"):
train_loss = 0.0
for batch in tqdm(train_loader, desc=f"Epoch {epoch + 1} in training", leave=False):
x, y = batch
x, y = x.to(device), y.to(device)
y_hat = model(x)
loss = criterion(y_hat, y)
train_loss += loss.detach().cpu().item() / len(train_loader)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch + 1}/{N_EPOCHS} loss: {train_loss:.2f}")
# Test loop
with torch.no_grad():
correct, total = 0, 0
test_loss = 0.0
for batch in tqdm(test_loader, desc="Testing"):
x, y = batch
x, y = x.to(device), y.to(device)
y_hat = model(x)
loss = criterion(y_hat, y)
test_loss += loss.detach().cpu().item() / len(test_loader)
correct += torch.sum(torch.argmax(y_hat, dim=1) == y).detach().cpu().item()
total += len(x)
print(f"Test loss: {test_loss:.2f}")
print(f"Test accuracy: {correct / total * 100:.2f
Now that we have this template, from now on, we can just focus on the model (ViT) that will have to classify the images with shape (N x 1 x 28 x 28).
Let’s start by defining an empty nn.Module. We will then fill this class step by step.
class MyViT(nn.Module):
def __init__(self):
# Super constructor
super(MyViT, self).__init__()
def forward(self, images):
pass
Forward pass
As Pytorch, as well as most DL frameworks, provides autograd computations, we are only concerned with implementing the forward pass of the ViT model. Since we have defined the optimizer of the model already, the framework will take care of back-propagating gradients and training the model’s parameters.
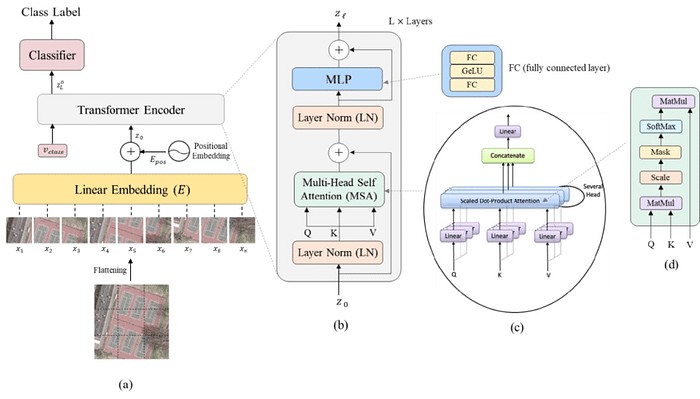
While implementing a new model, I like to keep a picture of the architecture on some tab. Here’s our reference picture for the ViT from Bazi et. al (2021)[reference]:
The architecture of the ViT with specific details on the transformer encoder and the MSA block. Keep this picture in mind. Picture from Bazi et. al.
By the picture, we see that the input image (a) is “cut” into sub-images equally sized.
Each such sub-image goes through a linear embedding. From then on, each sub-image is just a one-dimensional vector.
A positional embedding is then added to these vectors (tokens). The positional embedding allows the network to know where each sub-image is positioned originally in the image. Without this information, the network would not be able to know where each such image would be placed, leading to potentially wrong predictions!
These tokens are then passed, together with a special classification token, to the transformer encoders blocks, were each is composed of : A Layer Normalization (LN), followed by a Multi-head Self Attention (MSA) and a residual connection. Then a second LN, a Multi-Layer Perceptron (MLP), and again a residual connection. These blocks are connected back-to-back.
Finally, a classification MLP block is used for the final classification only on the special classification token, which by the end of this process has global information about the picture.
Let’s build the ViT in 6 main steps.
Step 1: Patchifying and the linear mapping
The transformer encoder was developed with sequence data in mind, such as English sentences. However, an image is not a sequence. It is just, uhm… an image… So how do we “sequencify” an image? We break it into multiple sub-images and map each sub-image to a vector!
We do so by simply reshaping our input, which has size (N, C, H, W) (in our example (N, 1, 28, 28)), to size (N, #Patches, Patch dimensionality), where the dimensionality of a patch is adjusted accordingly.
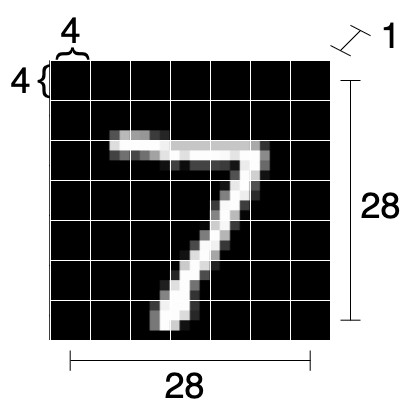
In this example, we break each (1, 28, 28) into 7×7 patches (hence, each of size 4×4). That is, we are going to obtain 7×7=49 sub-images out of a single image.
Thus, we reshape input (N, 1, 28, 28) to:
(N, P², HWC/P²) = (N, 7×7, 4×4) = (N, 49, 16)
Notice that, while each patch is a picture of size 1x4x4, we flatten it to a 16-dimensional vector. Also, in this case, we only had a single color channel. If we had multiple color channels, those would also have been flattened into the vector.
Raffiguration of how an image is split into patches. The 1x28x28 image is split into 49 (7×7) patches, each of size 16 (4x4x1)
We modify our MyViT class to implement the patchifying only. We create a method that does the operation from scratch. Notice that this is an inefficient way to carry out the operation, but the code is intuitive for learning about the core concept.
def patchify(images, n_patches):
n, c, h, w = images.shape
assert h == w, "Patchify method is implemented for square images only"
patches = torch.zeros(n, n_patches ** 2, h * w * c // n_patches ** 2)
patch_size = h // n_patches
for idx, image in enumerate(images):
for i in range(n_patches):
for j in range(n_patches):
patch = image[:, i * patch_size: (i + 1) * patch_size, j * patch_size: (j + 1) * patch_size]
patches[idx, i * n_patches + j] = patch.flatten()
return patches
The class constructor now lets the class know the size of our input images (number of channels, height and width). Note that in this implementation, the n_patches variable is the number of patches that we will find both in width and height (in our case it’s 7 because we break the image into 7×7 patches).
We can test the functioning of our class with a simple main program:
if __name__ == '__main__':
# Current model
model = MyViT(
chw=(1, 28, 28),
n_patches=7
)
x = torch.randn(7, 1, 28, 28) # Dummy images
print(model(x).shape) # torch.Size([7, 49, 16])
Now that we have our flattened patches, we can map each of them through a Linear mapping. While each patch was a 4×4=16 dimensional vector, the linear mapping can map to any arbitrary vector size. Thus, we add a parameter to our class constructor, called hidden_d for ‘hidden dimension’.
In this example, we will use a hidden dimension of 8, but in principle, any number can be put here. We will thus be mapping each 16-dimensional patch to an 8-dimensional patch.
We simply create a nn.Linear layer and call it in our forward function.
Notice that we run an (N, 49, 16) tensor through a (16, 8) linear mapper (or matrix). The linear operation only happens on the last dimension.
Step 2: Adding the classification token
If you look closely at the architecture picture, you will notice that also a “v_class” token is passed to the Transformer Encoder. What’s this?
Simply put, this is a special token that we add to our model that has the role of capturing information about the other tokens. This will happen with the MSA block (later on). When information about all other tokens will be present here, we will be able to classify the image using only this special token. The initial value of the special token (the one fed to the transformer encoder) is a parameter of the model that needs to be learned.
This is a cool concept of transformers! If we wanted to do another downstream task, we would just need to add another special token for the other downstream task (for example, classifying a digit as higher than 5 or lower) and a classifier that takes as input this new token. Clever, right?
We can now add a parameter to our model and convert our (N, 49, 8) tokens tensor to an (N, 50, 8) tensor (we add the special token to each sequence).
Notice that the classification token is put as the first token of each sequence. This will be important to keep in mind when we will then retrieve the classification token to feed to the final MLP.
Step 3: Positional encoding
As anticipated, positional encoding allows the model to understand where each patch would be placed in the original image. While it is theoretically possible to learn such positional embeddings, previous work by Vaswani et. al. [reference] suggests that we can just add sines and cosines waves.
In particular, positional encoding adds high-frequency values to the first dimensions and low-frequency values to the latter dimensions.
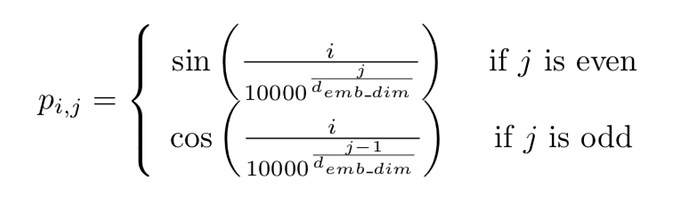
In each sequence, for token i we add to its j-th coordinate the following value:
Value to be added to the i-th tensor in its j-th coordinate. Image source.
This positional embedding is a function of the number of elements in the sequence and the dimensionality of each element. Thus, it is always a 2-dimensional tensor or “rectangle”.
Here’s a simple function that, given the number of tokens and the dimensionality of each of them, outputs a matrix where each coordinate (i,j) is the value to be added to token i in dimension j.
def get_positional_embeddings(sequence_length, d):
result = torch.ones(sequence_length, d)
for i in range(sequence_length):
for j in range(d):
result[i][j] = np.sin(i / (10000 ** (j / d))) if j
return result
if __name__ == "__main__":
import matplotlib.pyplot as plt
plt.imshow(get_positional_embeddings(100, 300), cmap="hot", interpolation="nearest")
plt.show()
Heatmap of Positional embeddings for one hundred 300-dimensional samples. Samples are on the y-axis, whereas the dimensions are on the x-axis. Darker regions show higher values.
From the heatmap we have plotted, we see that all ‘horizontal lines’ are all different from each other, and thus samples can be distinguished.
We can now add this positional encoding to our model after the linear mapping and the addition of the class token.
We define the positional embedding to be a parameter of our model (that we won’t update by setting its requires_grad to False). Note that in the forward method, since tokens have size (N, 50, 8), we have to repeat the (50, 8) positional encoding matrix N times.
Step 4: The encoder block (Part 1/2)
This is possibly the hardest step of all. An encoder block takes as input our current tensor [N, S, D] and outputs a tensor of the same dimensionality.
The first part of the encoder block applies Layer Normalization to our tokens, then a Multi-head Self Attention, and finally adds a residual connection.
Layer Normalization
Layer normalization is a popular block that, given an input, subtracts its mean and divides by the standard deviation.
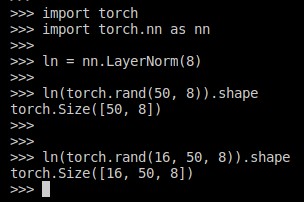
However, we commonly apply layer normalization to an (N, d) input, where d is the dimensionality. Luckily, also the Layer Normalization module generalizes to multiple dimensions, check this:
nn.LayerNorm can be applied in multiple dimensions. We can normalize fifty 8-dimensional vectors, but we can also normalize sixteen by fifty 8-dimensional vectors.
Layer normalization is applied to the last dimension only. We can thus make each of our 50×8 matrices (representing a single sequence) have mean 0 and std 1. After we run our (N, 50, 8) tensor through LN, we still get the same dimensionality.
Multi-head Self Attention
We now need to implement sub-figure c of the architecture picture. What’s happening there?
Simply put: we want, for a single image, each patch to get updated based on some similarity measure with the other patches. We do so by linearly mapping each patch (that is now an 8-dimensional vector in our example) to 3 distinct vectors: q, k, and v (query, key, value).
Then, for a single patch, we are going to compute the dot product between its q vector with all of the k vectors, divide by the square root of the dimensionality of these vectors (sqrt(8)), softmax these so-called attention cues, and finally multiply each attention cue with the v vectors associated with the different k vectors and sum all up.
In this way, each patch assumes a new value that is based on its similarity (after the linear mapping to q, k, and v) with other patches. This whole procedure, however, is carried out H times on H sub-vectors of our current 8-dimensional patches, where H is the number of Heads. If you’re unfamiliar with the attention and multi-head attention mechanisms, I suggest you read this nice post by Yasuto Tamura.
Once all results are obtained, they are concatenated together. Finally, the result is passed through a linear layer (for good measure).
The intuitive idea behind attention is that it allows modeling the relationship between the inputs. What makes a ‘0’ a zero are not the individual pixel values, but how they relate to each other.
Since quite some computations are carried out, it is worth creating a new class for MSA:
class MyMSA(nn.Module):
def __init__(self, d, n_heads=2):
super(MyMSA, self).__init__()
self.d = d
self.n_heads = n_heads
assert d
d_head = int(d / n_heads)
self.q_mappings = nn.ModuleList([nn.Linear(d_head, d_head) for _ in range(self.n_heads)])
self.k_mappings = nn.ModuleList([nn.Linear(d_head, d_head) for _ in range(self.n_heads)])
self.v_mappings = nn.ModuleList([nn.Linear(d_head, d_head) for _ in range(self.n_heads)])
self.d_head = d_head
self.softmax = nn.Softmax(dim=-1)
def forward(self, sequences):
# Sequences has shape (N, seq_length, token_dim)
# We go into shape (N, seq_length, n_heads, token_dim / n_heads)
# And come back to (N, seq_length, item_dim) (through concatenation)
result = []
for sequence in sequences:
seq_result = []
for head in range(self.n_heads):
q_mapping = self.q_mappings[head]
k_mapping = self.k_mappings[head]
v_mapping = self.v_mappings[head]
seq = sequence[:, head * self.d_head: (head + 1) * self.d_head]
q, k, v = q_mapping(seq), k_mapping(seq), v_mapping(seq)
attention = self.softmax(q @ k.T / (self.d_head ** 0.5))
seq_result.append(attention @ v)
result.append(torch.hstack(seq_result))
return torch.cat([torch.unsqueeze(r, dim=0) for r in result])
Notice that, for each head, we create distinct Q, K, and V mapping functions (square matrices of size 4×4 in our example).
Since our inputs will be sequences of size (N, 50, 8), and we only use 2 heads, we will at some point have an (N, 50, 2, 4) tensor, use a nn.Linear(4, 4) module on it, and then come back, after concatenation, to an (N, 50, 8) tensor.
Also notice that using loops is not the most efficient way to compute the multi-head self-attention, but it makes the code much clearer for learning.
Residual connection
A residual connection consists in just adding the original input to the result of some computation. This, intuitively, allows a network to become more powerful while also preserving the set of possible functions that the model can approximate.
We will add a residual connection that will add our original (N, 50, 8) tensor to the (N, 50, 8) obtained after LN and MSA. It’s time to create the transformer encoder block class, which will be a component of the MyViT class:
class MyViTBlock(nn.Module):
def __init__(self, hidden_d, n_heads, mlp_ratio=4):
super(MyViTBlock, self).__init__()
self.hidden_d = hidden_d
self.n_heads = n_heads
self.norm1 = nn.LayerNorm(hidden_d)
self.mhsa = MyMSA(hidden_d, n_heads)
def forward(self, x):
out = x + self.mhsa(self.norm1(x))
return out
Phew, that was quite some work! But I promise this was the hardest part. From now on, it’s all downhill.
With this self-attention mechanism, the class token (first token of each of the N sequences) now has information regarding all other tokens!
Step 5: The encoder block (Part 2/2)
All that is left to the transformer encoder is just a simple residual connection between what we already have and what we get after passing the current tensor through another LN and an MLP. The MLP is composed of two layers, where the hidden layer typically is four times as big (this is a parameter)
class MyViTBlock(nn.Module):
def __init__(self, hidden_d, n_heads, mlp_ratio=4):
super(MyViTBlock, self).__init__()
self.hidden_d = hidden_d
self.n_heads = n_heads
self.norm1 = nn.LayerNorm(hidden_d)
self.mhsa = MyMSA(hidden_d, n_heads)
self.norm2 = nn.LayerNorm(hidden_d)
self.mlp = nn.Sequential(
nn.Linear(hidden_d, mlp_ratio * hidden_d),
nn.GELU(),
nn.Linear(mlp_ratio * hidden_d, hidden_d)
)
def forward(self, x):
out = x + self.mhsa(self.norm1(x))
out = out + self.mlp(self.norm2(out))
return out
We can indeed see that the Encoder block outputs a tensor of the same dimensionality:
if __name__ == '__main__':
model = MyVitBlock(hidden_d=8, n_heads=2)
x = torch.randn(7, 50, 8) # Dummy sequences
print(model(x).shape) # torch.Size([7, 50, 8])
Now that the encoder block is ready, we just need to insert it in our bigger ViT model which is responsible for patchifying before the transformer blocks, and carrying out the classification after.
We could have an arbitrary number of transformer blocks. In this example, to keep it simple, I will use only 2. We also add a parameter to know how many heads does each encoder block will use.
class MyViT(nn.Module):
def __init__(self, chw, n_patches=7, n_blocks=2, hidden_d=8, n_heads=2, out_d=10):
# Super constructor
super(MyViT, self).__init__()
# Attributes
self.chw = chw # ( C , H , W )
self.n_patches = n_patches
self.n_blocks = n_blocks
self.n_heads = n_heads
self.hidden_d = hidden_d
# Input and patches sizes
assert chw[1]
assert chw[2]
self.patch_size = (chw[1] / n_patches, chw[2] / n_patches)
# 1) Linear mapper
self.input_d = int(chw[0] * self.patch_size[0] * self.patch_size[1])
self.linear_mapper = nn.Linear(self.input_d, self.hidden_d)
# 2) Learnable classification token
self.class_token = nn.Parameter(torch.rand(1, self.hidden_d))
# 3) Positional embedding
self.register_buffer('positional_embeddings', get_positional_embeddings(n_patches ** 2 + 1, hidden_d), persistent=False)
# 4) Transformer encoder blocks
self.blocks = nn.ModuleList([MyViTBlock(hidden_d, n_heads) for _ in range(n_blocks)])
def forward(self, images):
# Dividing images into patches
n, c, h, w = images.shape
patches = patchify(images, self.n_patches).to(self.positional_embeddings.device)
# Running linear layer tokenization
# Map the vector corresponding to each patch to the hidden size dimension
tokens = self.linear_mapper(patches)
# Adding classification token to the tokens
tokens = torch.cat((self.class_token.expand(n, 1, -1), tokens), dim=1)
# Adding positional embedding
out = tokens + self.positional_embeddings.repeat(n, 1, 1)
# Transformer Blocks
for block in self.blocks:
out = block(out)
return out
Once more, if we run a random (7, 1, 28, 28) tensor through our model, we still get a (7, 50, 8) tensor.
Step 6: Classification MLP
Finally, we can extract just the classification token (first token) out of our N sequences, and use each token to get N classifications.
Since we decided that each token is an 8-dimensional vector, and since we have 10 possible digits, we can implement the classification MLP as a simple 8×10 matrix, activated with the SoftMax function.
class MyViT(nn.Module):
def __init__(self, chw, n_patches=7, n_blocks=2, hidden_d=8, n_heads=2, out_d=10):
# Super constructor
super(MyViT, self).__init__()
# Attributes
self.chw = chw # ( C , H , W )
self.n_patches = n_patches
self.n_blocks = n_blocks
self.n_heads = n_heads
self.hidden_d = hidden_d
# Input and patches sizes
assert chw[1]
assert chw[2]
self.patch_size = (chw[1] / n_patches, chw[2] / n_patches)
# 1) Linear mapper
self.input_d = int(chw[0] * self.patch_size[0] * self.patch_size[1])
self.linear_mapper = nn.Linear(self.input_d, self.hidden_d)
# 2) Learnable classification token
self.class_token = nn.Parameter(torch.rand(1, self.hidden_d))
# 3) Positional embedding
self.register_buffer('positional_embeddings', get_positional_embeddings(n_patches ** 2 + 1, hidden_d), persistent=False)
# 4) Transformer encoder blocks
self.blocks = nn.ModuleList([MyViTBlock(hidden_d, n_heads) for _ in range(n_blocks)])
# 5) Classification MLPk
self.mlp = nn.Sequential(
nn.Linear(self.hidden_d, out_d),
nn.Softmax(dim=-1)
)
def forward(self, images):
# Dividing images into patches
n, c, h, w = images.shape
patches = patchify(images, self.n_patches).to(self.positional_embeddings.device)
# Running linear layer tokenization
# Map the vector corresponding to each patch to the hidden size dimension
tokens = self.linear_mapper(patches)
# Adding classification token to the tokens
tokens = torch.cat((self.class_token.expand(n, 1, -1), tokens), dim=1)
# Adding positional embedding
out = tokens + self.positional_embeddings.repeat(n, 1, 1)
# Transformer Blocks
for block in self.blocks:
out = block(out)
# Getting the classification token only
out = out[:, 0]
return self.mlp(out) # Map to output dimension, output category distribution
The output of our model is now an (N, 10) tensor. Hurray, we are done!
Results
We change the only line in the main program that was previously undefined.
model = MyVit((1, 28, 28), n_patches=7, n_blocks=2, hidden_d=8, n_heads=2, out_d=10).to(device)
We now just need to run the training and test loops and see how our model performs. If you’ve set torch seed manually (to 0), you should get this printed:
Training losses, test loss, and test accuracy obtained.
And that’s it! We have now created a ViT from scratch. Our model achieves ~80% accuracy in just 5 epochs and with few parameters.
You can find the full script at the following link. Consider giving a clap if you found the story useful and let me know if you think something was unclear!